
はじめに
Synology の DS218plus の HDD を 4TB -> 8TB に更新した際に、内蔵2基 + Hyper Backup 用1基の合計3基 (SG, WD1, WD2) の 4TB HDD が遊休となりました。これらの HDD を使用して、Linux の様々なファイルシステムの違いや Software RAID を組んだ場合のディスクのアクセス速度を測定しようと考えています。

前回の記事「その3【fio編】」では、Linux の Ext4 filesystem で fio を使用して、ディスクのアクセス速度を測定してみました。

その結果、fio では測定条件をある程度決める事で、再現性がありバラツキの少ない安定したアクセス速度の測定が出来る事がわかりました。
- Windows 版 CrystalDiskMark (CDM) と同様の条件で測定し、多少の違いはありますが概ね同様の結果が得られました。
- データサイズが 3GB 以上の条件では diskspd for linux と比べてバラツキが小さく、再現性の高い結果が得られました。
- startdelay と ramp_time オプションを適切に設定する必要がありました。runtime を伸ばしてもバラツキは小さくなりませんでした。特に Write に関しては最適値があり、大きくしてもバラツキは小さくなりませんでした。
今回の記事では、4つの filesystem (Ext4、XFS、Btrfs、JFS) について、fio を使用してアクセス速度を測定しました。
Linux では空きメモリを積極的にディスクの Cache として使用します。できるだけ Cache を使用しない場合 (O_DIRECT, non-cached) と、Cache を最大限に活用した場合 (cached) の二種類の条件でアクセス速度を測定し、filesystem の特徴について調べてみました。
なお「各 filesystem の説明は置いといて結果を見たい」という方は、もくじから結果の部分を参照下さい。
2024年1月19日追記:
その5です。mdadm で RAID 0 (2, 3基) / RAID 1 / RAID 5 の RAID array を作成し、3種類 (Ext4, XFS, Btrfs) の filesystem のアクセス速度を比較しました。

各 filesystem の特徴
Linux の開発当初は Minix 用の filesystem を使用していましたが、その後、Ext1、Ext2、Ext3、ReiserFS 等を経て、現在では Ext4 が主流の filesystem となっています。Ext4 以外にも、現在の Linux では複数の filesystem を選択する事が出来るようになりました。
私自身は、普段は Ext4 を主に使用しています。特に拘りがある訳ではなく、Ext2 時代から使用しているので慣れている事と、どのディストリビューションを選択したとしてもインストーラが必ず対応している事から、深く考えずに選択していました。
今回は良い機会ですので、使用する 4 種類の filesystem について、特徴を調べて比較してみました。
なお、ZFS も興味深い filesystem ですが、Storage Pool を使用する事が default になっているようですので、Btrfs の Storage Pool や mdadm & LVM と比較する際に試してみる予定です。
Ext4 (fourth extended file system)


Ext4 was released as a functionally complete and stable filesystem in Linux 2.6.28, and it's getting included in all the modern distros (in some cases as the default fs), so if you are using a modern distro, it's possible that you already have Ext4 support and you don't need to modify your system to run Ext4.
Ext4は、Linux 2.6.28で機能的に完全で安定したファイルシステムとしてリリースされ、すべての最新ディストロに(場合によってはデフォルトのfsとして)含まれている。
https://ext4.wiki.kernel.org/index.php/Ext4_Howto
前述のように、Linux の初期の開発は Minix の filesystem を使用して Cross Build で始まり、最低限の機能を実装して、Linux 単独で起動できるようになりました。
最初期の filesystem は Ext1 で、Ext2、Ext3を経て、現在の Ext4 filesystem に繋がっています。
- Ext1 : 1992年4月 Linux 0.93c Minix filesystem の不具合や制限の解消 (filename の長さ、容量制限)
- Ext2 : 1993年1月 Linux 0.99 timestamp の個別設定 (file access, i-node 変更, データ変更)
- Ext3 : 2001年11月 Linux 2.4.15 ジャーナルの追加、オンライン容量拡張、大容量ファイルのHTree インデックス化
- Ext4 : 2006年10月 Linux 2.6.19 & 2.6.28 ストレージ上限の拡張、パフォーマンスの改善
私が Linux を使い始めたのは Ext2 の時代ですが、HDD の容量の増加に伴い起動時の fsck に長時間を要す事に困っていました。Ext3 でジャーナルが追加された事によって、fsck の時間が劇的に改善された記憶があります。
Ext4 の特徴は以下の内容です。(英語版 Wikipedia より抜粋)
- 大容量メディアや大容量ファイルへの対応
- ブロックマッピングの代わりにエクステントの使用
- 後方互換性 (Ext3, Ext2)
- サブディレクトリ数に制限なし、HTree インデックスによる高速化
- チェックサム付ジャーナル
- メタデータのチェックサム
- ファイルシステムチェック (fsck) の高速化
- マルチブロックアロケータによるフラグメンテーションの防止
- ナノ秒単位のタイムスタンプの記録
- Project ID 単位でのディスク使用量制限 (quota)
- 透過的暗号化のサポート
- 遅延初期化
- 書き込みバリア
これまで何気なく使用していた Ext4 ですが、Linux で広く使われている (ほぼ defact standard) だけあり、豊富な機能を有しています。
XFS (eXtents File System)


XFS is a high-performance 64-bit journaling file system created by Silicon Graphics, Inc (SGI) in 1993. It was the default file system in SGI's IRIX operating system starting with its version 5.3. XFS was ported to the Linux kernel in 2001; as of June 2014, XFS is supported by most Linux distributions; Red Hat Enterprise Linux uses it as its default file system.
XFSは1993年にSilicon Graphics, Inc (SGI)によって作成された高性能な64ビットのジャーナリングファイルシステムであり、SGIのIRIXオペレーティングシステムのバージョン5.3からデフォルトのファイルシステムとなっている。XFSは2001年にLinuxカーネルに移植された。2014年6月現在、XFSはほとんどのLinuxディストリビューションでサポートされており、Red Hat Enterprise Linuxはデフォルトのファイルシステムとして使用している。
https://en.wikipedia.org/wiki/XFS
XFS は Gentoo / RedHat 系では良く使われているようです。私はどちらかといえば Debian 系の distribution を使用する事が殆どですので、これまで XFS は使用したことがありませんでした。
Silicon Graphics, Inc (SGI) の IRIX (SystemV 系の UNIX) で使用されていた filesystem を GPL で公開したのが 1999年5月、Linux に移植して使用できるようにしたのが 2001年、Linux kernel 2.6 / 2.4 に merge されたのが 2004年2月で、それ以降に各 distribution での対応が進んだとの事です。
XFS の特徴は以下の内容です。(英語版 Wikipedia より抜粋)
- 大容量メディアや大容量ファイルへの対応
- ジャーナリング
- アロケーショングループ
- RAID0 使用時のデータ、i-node、ジャーナル書き込みの最適化によるスループット向上
- エクステント使用によるフラグメンテーション防止、B+ tree 使用による高速化
- 可変ブロックサイズ 512 bytes ~ 64 KB
- 遅延配置 (バッファキャッシュとエクステントを使用)
- 疎な巨大ファイルの作成
- 拡張属性への対応
- Direct I/O (non-cached I/O)
- スナップショット (XFS 単体の機能ではない) I/O を停止させる xfs_freeze と、Linux なら LVM との組み合わせで使用する。(最近の Linux では VFS レベルでサポートされて、Linux 2.6.29 以降では他の filesystem もサポートされた)
- オンラインデフラグメンテーション
- オンラインディスク拡張
Linux kernel に merge されてから約20年が経過しているのですね。RAID0 使用時のスループット向上、及びスナップショット (他の filesystem 含む) については、mdadm + LVM を使用した際に確認してみます。
Btrfs (B-tree file system)


BTRFS is a modern copy on write (COW) filesystem for Linux aimed at implementing advanced features while also focusing on fault tolerance, repair and easy administration.
BTRFSは、Linux向けの最新のコピーオンライト(COW)ファイルシステムであり、高度な機能の実装を目指すと同時に、耐障害性、修復性、容易な管理にも重点を置いている。
https://btrfs.readthedocs.io/en/latest/Introduction.html
2009年3月に Btrfs は Linux 2.6.29 に取り込まれました。約15年前なので結構昔ですね。
Btrfs は、私は Synology の NAS で使用しています。過去に HDD を 4TB から 8TBに更新した際に、HDD の中身を調査した事がありました。はてなブログの私の記事へのリンクです。

Synology の SHR (Synology Hybrid RAID) は、mdadm + LVM で構成したストレージプールからパーティションを準備して Btrfs でフォーマットされています。
他の filesystem との大きな違いは、耐障害性への対策として、ジャーナルの代わりに Copy-On-Write (COW) を採用している所です。実際に書き込まれる (コミット) 前のデータを、ジャーナルと呼ばれるデータ構造に記録しておくか、書き換えずに新しく書き込んで古いデータと参照先を変更するか、の違いです。COW を採用する事により、ある時点でのスナップショットやスナップショット間の増分バックアップを容易に取得する事が出来ます。
A journaling file system is a file system that keeps track of changes not yet committed to the file system's main part by recording the goal of such changes in a data structure known as a "journal", which is usually a circular log. In the event of a system crash or power failure, such file systems can be brought back online more quickly with a lower likelihood of becoming corrupted.
ジャーナリングファイルシステムは、ファイルシステムのメイン部分にまだコミットされていない変更のゴールを「ジャーナル」として知られるデータ構造に記録することで追跡するファイルシステムであり、通常は循環ログである。システムのクラッシュや電源障害が発生した場合、このようなファイルシステムは、破損する可能性が低く、より迅速にオンラインに戻すことができます。
https://en.wikipedia.org/wiki/Journaling_file_system
Copy-on-write (COW), sometimes referred to as implicit sharing or shadowing, is a resource-management technique used in computer programming to efficiently implement a "duplicate" or "copy" operation on modifiable resources[3] (most commonly memory pages, storage sectors, files, and data structures).
コピー・オン・ライト(COW)は、暗黙の共有やシャドウイングと呼ばれることもあり、コンピュータ・プログラミングで使用されるリソース管理手法で、変更可能なリソース(最も一般的なのは、メモリ・ページ、ストレージ・セクタ、ファイル、データ構造)に対して「複製」または「コピー」操作を効率的に実装するために使用される。
https://en.wikipedia.org/wiki/Copy-on-write#In_computer_storage
Btrfs の特徴は以下の内容です。(英語版 Wikipedia より抜粋)
- Copy-On-Write を使用する事による自己修復
- オンラインの断片化解消、自動断片化解消の mount option
- オンラインのボリュームサイズの拡大、縮小
- オンラインのブロックデバイスの追加と取外し
- オンラインの負荷分散
- オフラインのファイルシステムチェック
- オンラインのデータスクラビング (データ整合性のチェックと自動修正)
- RAID サポート (mdadm を使用せず) RAID0 / 1 / 10 / 5 / 6。(Wikipedia では RAID5 / 6 は製品用途には適さないと記載されていますが、2017年に修正されているとの記載があります)
- サブボリューム (ボリュームの一部を別管理できる)
- 透過的な圧縮 (zlib, LZO, ZSTD)
- サブボリュームのスナップショット
- ファイルのクローン (実体は一つで COW を使用して cp)
- データとメタデータのチェックサム
- 稼働状態で Ext3 / Ext4 からの Btrfs への変換、元に戻す事も可能
- 読み取り専用領域の複数ディレクトリの同一箇所への重ねたマウント (Union mounting)
- SSD の TRIM による領域開放
- スナップショット間の差分の送信と受信
- 増分バックアップ
- データの重複排除 (外部ツール)
- Swap と Swap ファイルを使用可能
Btrfs は、上記の特徴にもあるように、ブロックデバイスの追加・取外しのような Storage pool機能や RAID 機能を (mdadm や LVM ではなく) filesystem の機能として有しています。また、これらの機能を使用せずに、ブロックデバイスを単一の filesystem としてフォーマットする事も可能です。
Synology Hybrid RAID では mdadm & LVM の環境の上で Btrfs を使用していましたが、今回のディスクのアクセス速度の測定では、一つのブロックデバイスを Btrfs でフォーマットしてテストします。
Arch Linux Wiki は他のディストリビューションでも参考になる良記事が多いです。

Btrfs を長年使われている方の記事です。参考になりました。

次回以降の記事で、Btrfs の Storage pool や RAID の機能を使用してみたいと考えています。
JFS (Journaled File System)


IBM's journaled file system technology, currently used in IBM enterprise servers, is designed for high-throughput server environments, key to running intranet and other high-performance e-business file servers. IBM is contributing this technology to the Linux open source community with the hope that some or all of it will be useful in bringing the best of journaling capabilities to the Linux operating system.
IBMのジャーナル・ファイル・システム・テクノロジーは、現在IBMエンタープライズ・サーバーで使用されており、イントラネットやその他の高性能e-ビジネス・ファイル・サーバーを実行する上で鍵となる、高スループット・サーバー環境向けに設計されている。IBMは、Linuxオペレーティング・システムに最高のジャーナリング機能をもたらすために、この技術の一部または全部が役立つことを期待して、Linuxオープンソース・コミュニティにこの技術を提供している。
https://jfs.sourceforge.net/
JFS は IBM が開発した filesystem で、AIX (IBM製の UNIX) や OS/2 (懐かしい…) で使用されていまいした。1999年12月に Open Source (GPL) となり、Linux には 2001年6月に安定版が公開されました。Linux 2.4.18pre9-ac4 以降で対応しています。AIX 版では JFS1、JFS2 の2世代の JFS が存在していますが、Linux に移植されたのは第二世代の JFS2 で呼称も "2" の無い JFS になっています。
JFS の特徴は以下の内容です。(英語版 Wikipedia より抜粋)
- ジャーナリングファイルシステム
- ディレクトリの管理に B+ tree を使用し高速化
- 動的な i-node の配置
- エクステントの使用による断片化防止
- アロケーショングループ (AG) の使用による I/O 性能の向上
Wikipedia には透過的圧縮とコンカレント I/O (Concurrent input/output, CIO) の記載がありますが AIX のみの対応のようです。CIO は使ってみたかったのですが、Linux の jfsutils の man page には見つかりませんでした。
比較表
各ファイルシステムを比較した一覧表を以下に示します。(英語版 Wikipedia より抜粋)
| 項目 | Ext4 | XFS | Btrfs | JFS |
|---|---|---|---|---|
| Linux への導入年月 | 2008/10 | 2004/2 | 2009/3 | 2001/6 |
| Linux kernel | 2.6.28 | 2.4.25 | 2.6.29 | 2.4.18pre9-ac4 |
| 最大ボリュームサイズ | 1 EiB | 1 EiB -1 byte | 16 EiB | 32 PiB |
| 最大ファイルサイズ | 16-256 TiB | 1 EiB -1 byte | 16 EiB | 32 PiB |
| 最大ファイル数 | 40億 | 2^64 | 2^64 | No Limit |
| ファイル名最大長 | 255 | 255 | 255 | 255 |
| 透過的圧縮 | no | no | yes | no |
| 透過的暗号化 | yes | no | Planned | no |
| ジャーナル | yes | yes | no | yes |
| Copy-On-Write | no | no | yes | no |
| ディレクトリ構成 | Linked list, hashed B-tree | B+ trees | B tree | B+ tree |
| ファイル割当構成 | Extents / Bitmap | Extents | Extents | Bitmap / Extents |
| 領域拡張 (expand) | yes (resize2fs) | yes (xfs_growfs) | yes (btrfs filesystem resize) | yes (mount -o resize) |
| 領域縮小 (shrink) | yes (resize2fs) | no | yes (btrfs filesystem resize) | no |
| 特徴 | Linux の Defact standard Ext2, Ext3 との 互換性 | SGI が IRIX 用に 開発 | Linux 用に新規に開発 (参加企業多数) 耐障害性・修復機能・容易な管理 | IBM が AIX 用に 開発 |
Filesystem に関して素人がまとめた表ですので、間違いがあればご指摘下さい。
Linux への導入年は、古い順に JFS -> XFS -> Ext4 -> Btrfs になります。とはいえ、Ext4 は前身の Ext3 等もあり後方互換性もありますので、「昔から存在していた」という感覚があります。Btrfs にしても約15年前に導入されていますので、どの filesystem も長く使われています。
T (テラ, 10^12)、P (ペタ, 10^15)、E (エクサ, 10^18) ですので、最大ボリュームサイズについては現時点では制限に達するまでの容量を個人で確保する方が難しいかと思います。同様に、最大ファイルサイズや最大ファイル数の制限についても、個人ユースでは十分かと思います。(私の世代だとフロッピーディスク 640 kB ~ 1 MB、HDD 20 MB とか普通でしたので隔世の感があります)
透過的圧縮は Btrfs のみ対応しています。3種類のアルゴリズムから選択できます。JFS は AIX のみの対応で、Linux 用 JFS では透過的圧縮には対応していません。
Btrfs は、Storage Pool や RAID 機能を filesystem の機能として有していますので、本来なら ZFS と比較するべきだと思います。とはいえ、Block device 単独でも使用できますので、今回の比較に入れました。
透過的暗号化は Ext4 のみ対応していますが、Linux system 全体を暗号化する場合には dm-crypt を使用するのが良さそうです。Arch Linux の該当ページへのリンクです。

そのうち試してみたいと考えています (Arch Linux の install 含め) 。
20240112 追記:
領域拡張 (expand) / 縮小 (shrink) には、Ext4 と Btrfs のみ両方対応しています。XFS と JFS は領域拡張のみの対応です。
各 filesystem の準備
下記の準備編では Ext4 のパーティションの作成方法について記載しました。
繰り返しますが、初めに注意事項です。
gdisk によるパーティションの確保については上記のリンク先に記載しました。パーティションは分割せず、4TB 全体を一つのパーティションと確保して各 filesystem でフォーマットしました。
各 filesystem でフォーマットするコマンドについて以下に記載します。/dev/sda1 を例として記載していますが、該当する block device に読み替えて下さい。各 filesystem をフォーマットするコマンドが含まれるパッケージも参考の為に記載しました。
以前に使用していた filesystem が残っているメッセージが表示されますので、強制的にフォーマットする option も追記しました。
# Ext4
$ dpkg -S /sbin/mkfs.ext4
e2fsprogs: /sbin/mkfs.ext4
$ sudo mkfs.ext4 -F /dev/sda1
# XFS
$ dpkg -S /sbin/mkfs.xfs
xfsprogs: /sbin/mkfs.xfs
$ sudo mkfs.xfs -f /dev/sda1
# Btrfs
$ dpkg -S /sbin/mkfs.btrfs
btrfs-progs: /sbin/mkfs.btrfs
$ sudo mkfs.btrfs -f /dev/sda1
# JFS
$ dpkg -S /sbin/mkfs.jfs
jfsutils: /sbin/mkfs.jfs
$ sudo mkfs.jfs /dev/sda1mount 方法と一般ユーザーで書き込めるようにする chown コマンドについては、準備編の記事を参照下さい。
fio の測定条件と測定用スクリプト
前回の記事で、安定したアクセス速度を測定できる fio の測定条件について調べました。
今回は各 filesystem で測定を繰り返しますので、fio の設定ファイルを変更しました。前回と同じファイル名で fio_setting.fio としました。
- size と runtime は各条件で共通なので [global] に含めました。
- 各条件毎に startdelay と ramp_time を設定しました。
[global]
ioengine=libaio
stonewall
group_reporting
size=3Gi
runtime=60
[SEQ1MQ8T1_READ]
startdelay=5
ramp_time=5
rw=read
bs=1Mi
iodepth=8
numjobs=1
[SEQ1MQ8T1_WRITE]
startdelay=5
ramp_time=20
rw=write
bs=1Mi
iodepth=8
numjobs=1
[SEQ1MQ1T1_READ]
startdelay=5
ramp_time=5
rw=read
bs=1Mi
iodepth=1
numjobs=1
[SEQ1MQ1T1_WRITE]
startdelay=5
ramp_time=20
rw=write
bs=1Mi
iodepth=1
numjobs=1
[RND4KQ32T1_READ]
startdelay=5
ramp_time=5
rw=randread
bs=4Ki
iodepth=32
numjobs=1
[RND4KQ32T1_WRITE]
startdelay=20
ramp_time=5
rw=randwrite
bs=4Ki
iodepth=32
numjobs=1
[RND4KQ1T1_READ]
startdelay=5
ramp_time=5
rw=randread
bs=4Ki
iodepth=1
numjobs=1
[RND4KQ1T1_WRITE]
startdelay=30
ramp_time=5
rw=randwrite
bs=4Ki
iodepth=1
numjobs=1この設定ファイルを使用して、複数回の測定を実行する bash script を以下に示します。名前は (安易ですが) fio_measure2.sh としました。fio の測定結果と、fio 終了後に sync に要する時間を測定しています。
#! /bin/bash
# fio は apt で入れる
FIO="fio"
FIO_JOBFILE="./fio_setting.fio"
TIME_CMD="/usr/bin/time -f %e"
# 引数の数チェック : 6
if [ "$#" != 6 ]
then
echo "ERROR!"
echo "You must provice five args."
echo " 1: Measurement Type : SEQ1MQ8T1, ..."
echo " 2: Target directory : /media/user/target/ etc."
echo " 3: Counts : Repeat Measuring times."
echo " 4: READ or WRITE : Measurement Type."
echo " 5: O_DIRECT or CACHE : non-cache or use-cache."
echo " 6: CLEAR or NONE : Data Clear or none."
exit 1
fi
# CrystalDiskMark 同等の測定方法の指定
# パラメータを変更したい場合には case ... esac をコメント
TYPE=$1
case ${TYPE} in
"SEQ1MQ8T1" )
;;
"SEQ1MQ1T1" )
;;
"RND4KQ32T1" )
;;
"RND4KQ1T1" )
;;
*)
echo "ERROR!"
echo "Type Miss match. Do not use Type ${TYPE}"
exit 1
esac
# Data size は JOBFILE で指定する
# Target Directory の指定
TEST_DIR=$2
DIR_NAME=`basename ${TEST_DIR}`
# Directory の存在確認
if [ ! -d ${TEST_DIR} ]
then
echo "ERROR!"
echo "Data Directory not exists."
exit 1
fi
# Filesystem の確認
FILESYSTEM=`df -T ${TEST_DIR} | awk 'NR==2{print $2}'`
# 測定回数の指定
COUNTS=$3
if [ ${COUNTS} -lt 1 ] # 1以上を指定
then
echo "ERROR!"
echo "Measure counts >=1."
exit 1
fi
# Read / Write の指定
R_W=$4
if [ ${R_W} = "READ" ]
then
w_OP="read"
else
w_OP="write"
fi
# O_DIRECT or CACHE
CACHE=$5
if [ ${CACHE} = "O_DIRECT" ]; then
# Btrfs : space_cache 無効, CoW 無効で mount する
# JFS : sync 有効で mount する
direct_OP="--direct=1 --invalidate=1"
else # CACHE
# READ の場合は invalidate=0 も必要
direct_OP="--buffered=1 --invalidate=0"
fi
# 後始末のチェック
CLEAR_FLG=$6
if ! ( [ ${CLEAR_FLG} = "CLEAR" ] || [ ${CLEAR_FLG} = "NONE" ] )
then
echo "Select CLEAR or NONE"
exit 1
fi
# JOBFILE に CDM 相当の設定は記載されている
# 測定用データの作成 : 必ず最初に作成するようにする
fio --create_only=1 --directory=${TEST_DIR} \
--section=${TYPE}_${R_W} ${FIO_JOBFILE} 2>&1 > /dev/null
sync
sleep 15
# CSV で出力
# title line
echo -n "No.,Type,Read/Write,Target,cache,filesystem,result"
if [ ${FILESYSTEM} = "jfs" ] && [ ${CACHE} = "CACHE" ] && [ ${TYPE:0:5} = "RND4K" ] && [ ${R_W} = "WRITE" ]; then
# jfs の CACHE RND4K の場合は sync を行わない
echo
else
echo ",sync_sec"
fi
for i in `seq ${COUNTS}`; do
echo -n "${i},${TYPE},${R_W},${DIR_NAME},${CACHE},${FILESYSTEM},"
# measure awk printf で改行しないように
${FIO} --directory=${TEST_DIR} ${direct_OP} \
--section=${TYPE}_${R_W} ${FIO_JOBFILE} \
--output-format=terse | awk -F ';' '{printf ($7+$48) / 1000 }'
if [ ${FILESYSTEM} = "jfs" ] && [ ${CACHE} = "CACHE" ] && [ ${TYPE:0:5} = "RND4K" ] && [ ${R_W} = "WRITE" ]; then
# jfs の CACHE RND4K の場合は sync を行わない
echo
else
# sync_time
echo -n ","
echo -n `${TIME_CMD} sync`
fi
done
# 後始末
if [ ${CLEAR_FLG} = "CLEAR" ]
then
if ls ${TEST_DIR%/}/RND* > /dev/null 2>&1
then
rm -f ${TEST_DIR%/}/RND*
fi
if ls ${TEST_DIR%/}/SEQ* > /dev/null 2>&1
then
rm -f ${TEST_DIR%/}/SEQ*
fi
fiJFS で Cache 使用、RND4K Write の場合に sync に要する時間を測定しない理由については後述します。
この script を使用した測定の例です。/media/hiro 以下にフォルダを作成し、各 filesystem でフォーマットしたパーティションを mount しています。
# Ext4 SEQ1MQ8T1 READ O_DIRECT
$ ./fio_measure2.sh SEQ1MQ8T1 /media/hiro/WD2/ 5 READ O_DIRECT CLEAR
No.,Type,Read/Write,Target,cache,filesystem,result,sync_sec
1,SEQ1MQ8T1,READ,WD2,O_DIRECT,ext4,176.979,0.08
2,SEQ1MQ8T1,READ,WD2,O_DIRECT,ext4,179.341,0.08
3,SEQ1MQ8T1,READ,WD2,O_DIRECT,ext4,177.739,0.04
4,SEQ1MQ8T1,READ,WD2,O_DIRECT,ext4,177.564,0.03
5,SEQ1MQ8T1,READ,WD2,O_DIRECT,ext4,178.213,0.03
# JFS SEQ1MQ8T1 READ CACHE
$ ./fio_measure2.sh SEQ1MQ8T1 /media/hiro/SG/ 5 READ CACHE CLEAR
No.,Type,Read/Write,Target,cache,filesystem,result,sync_sec
1,SEQ1MQ8T1,READ,SG,CACHE,jfs,185.593,0.04
2,SEQ1MQ8T1,READ,SG,CACHE,jfs,5386.52,0.03
3,SEQ1MQ8T1,READ,SG,CACHE,jfs,9418.35,0.03
4,SEQ1MQ8T1,READ,SG,CACHE,jfs,8344.11,0.03
5,SEQ1MQ8T1,READ,SG,CACHE,jfs,8689.86,0.03
# JFS RND4KQ32T1 WRITE CACHE
$ ./fio_measure2.sh RND4KQ32T1 /media/hiro/SG/ 5 WRITE CACHE CLEAR
No.,Type,Read/Write,Target,cache,filesystem,result
1,RND4KQ32T1,WRITE,SG,CACHE,jfs,474.092
2,RND4KQ32T1,WRITE,SG,CACHE,jfs,1553.44
3,RND4KQ32T1,WRITE,SG,CACHE,jfs,1537.5
4,RND4KQ32T1,WRITE,SG,CACHE,jfs,1555.75
5,RND4KQ32T1,WRITE,SG,CACHE,jfs,1516.74
結果は CSV で出力するようにして、各条件で測定した結果を Excel で集計しました。
Cache を使用した場合に 1回目、2回目のアクセス速度が低くなる状況もありました。平均を取る際にはアクセス速度が低い結果は除外しました。
fio の測定結果 1 : できるだけ Cache を使用しない条件
始めに、できるだけ Cache を使用しない条件でディスクのアクセス速度を測定しました。同一ディスクであれば、Cache を使用しなければ、同じようなアクセス速度の結果が得られるはずです。
このアクセス速度が、Cache が最大限使われた後に連続で Read / Write した時に漸近する最小の速度となります。
4種類の filesystem について fio で測定を進めましたが、一部不具合のような現象がありましたので、その対処を行ってから全ての測定を実施しました。始めに、その不具合の状況と対処について説明します。
測定不具合の状況と対処 (Btrfs, JFS)
fio の --direct=1 (O_DIRECT) を使用して、Cache を使用せずにディスクのアクセス速度を測定しました。その中で、Ext4 と XFS では問題なく測定できたのですが、Btrfs と JFS の RND4K の Write の測定時に不可解な現象が発生しました。
O_DIRECT を使用した場合の不具合の内容
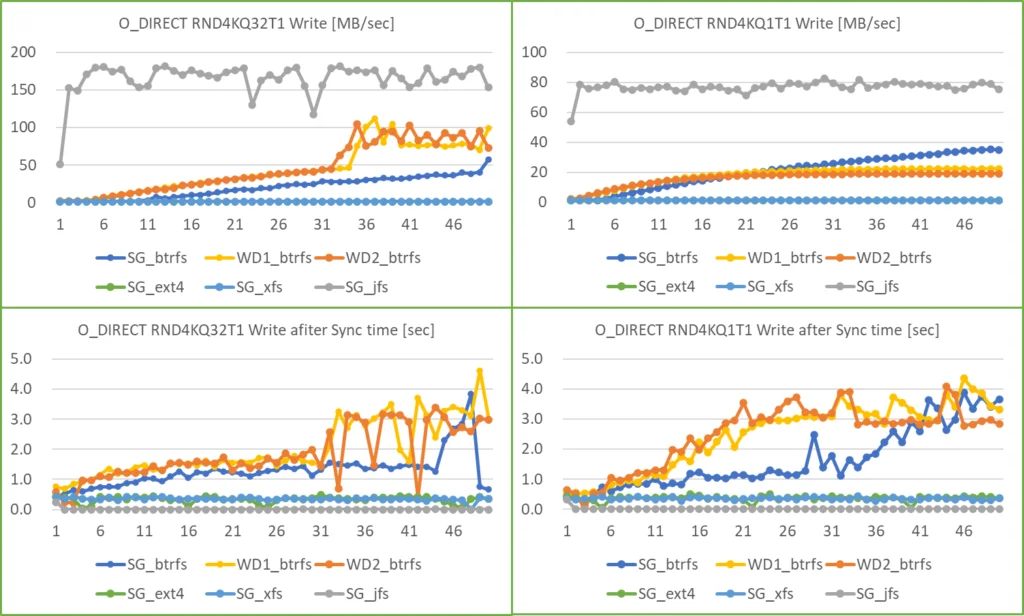
下図は、mkfs に option を付けずに filesystem を作成、mount の際も特別な option を付けずに mount し、RND4KQ32T1 と RND4KQ1T1 の Write を50回測定した時のトレンドです。
Ext4 と XFS はほぼ変わらない結果で、アクセス速度は 1.3 ~ 1.4 MB/sec、sync に要する時間は 0.4 sec 前後でした。(下図では縦軸スケールの関係で、ほぼゼロの値となっています)
アクセス速度と sync に要した時間
それに対して、Btrfs と JFS の RND4KQ32T1 Write では、
- Btrfs は、測定直後から徐々にアクセス速度が上昇し、最終的には 100 MB/sec まで上昇、それに伴って終了時の sync に要する時間が 3~5秒を要していました。
- JFS は測定初期から 150 ~ 200 MB/sec のアクセス速度で推移していました。こちらは終了時の sync に要する時間はほぼゼロでした。
RND4KQ1T1 Write では、
- Btrfs は、RND4KQ32T1 と同様に徐々にアクセス速度が増加し、最終的には 20 ~ 40 MB/sec まで上昇、それに伴って終了時の sync に要する時間が 3~4秒を要していました。
- JFS は測定初期から 80 MB/sec のアクセス速度で推移していました。こちらも終了時の sync に要する時間はほぼゼロでした。
Btrfs と JFS の結果は、出来るだけ Cache を使用しない条件で測定しているアクセス速度としては、異常な程に速い結果であり、個人的にはありえない結果と感じました。これを修正するために、この二つの filesystem では測定条件を変更する事にしました。
Btrfs の mount option の変更
Btrfs の場合、次の二つのの影響により、O_DIRECT を有効にしても Random Access の際に Cache が効いてしまいます。(Sequential では影響しません)
- Space cache
- CoW (Copy on Write)
もちろん、この二つの効果により Btrfs の Cache を有効利用したアクセス速度は向上するのですが、O_DIRECT を有効にしても回避できない為、ディスクのアクセス速度のみを評価したい場合には不都合です。
これら 2つの項目は、mount option で回避できます。
$ sudo mount -t btrfs -o clear_cache,nospace_cache,nodatacow /dev/sda1 /media/hiro/btrfsnodatacow は、次回の mount で記載しなければ有効になります。
nospace_cache を指定した場合には、次回の mount の際にも space_cache が使用されなくなります。その場合には、space_cache を使用する option を追記します。
$ sudo mount -t btrfs -o space_cache=v2 /dev/sda1 /media/hiro/btrfsJFS の mount option の変更
JFS の場合も、Btrfs と同様に Random Access の際に Cache が効いてしまいます。filesystem 作成時の mkfs.jfs にも、mount 時にも、Cache を回避する為の option の選択肢がありません。
JFS では、mount の filesystem 非依存の option である sync option を追記しました。
$ sudo mount -t jfs -o sync /dev/sda1 /media/hiro/jfssync オプションは Sequential Access には影響しないようです。
Btrfs, JFS mount option 変更後
Btrfs と JFS の mount option を追加した場合の結果です。
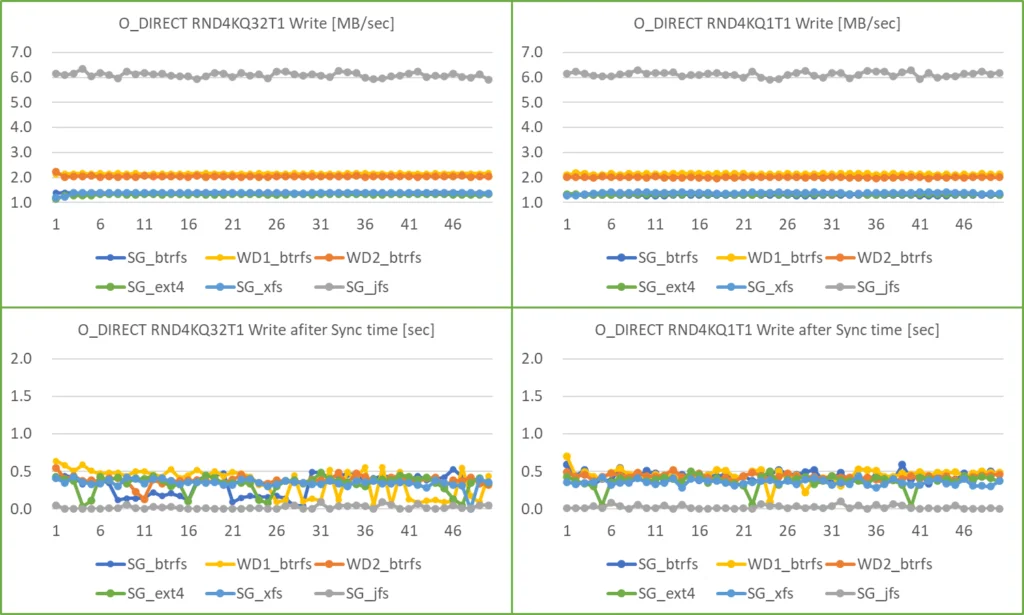
アクセス速度と sync に要した時間
- Btrfs のアクセス速度が上昇する傾向はなくなりました。また、測定終了後の sync に要する時間も 0.5 sec 以内に収まり安定しました。
- JFS では、mount に sync option を付加しても、他の filesystem と比較して3~6倍の 6 MB/sec のアクセス速度になりました。とはいえ、測定終了後の sync に要する時間はほぼゼロです。断言はできませんが JFS の特徴なのかも知れません。
CDM 相当の条件での測定経過 (O_DIRECT)
前項までの対策をとった上で、CrystalDiskMark 相当の条件でディスクのアクセス速度を測定しました。結果について以下にグラフで示します。
特に記載のない場合には N=10 の平均値です。
SEQ1MQ8T1 Read / Write
機種間の差を見ると若干 SG のアクセス速度が速いですが、ほぼ横並びと言えるかと思います。Read 180 ~ 187 MB/sec、Write 176 ~ 183 MB/sec でした。


SEQ1MQ1T1 Read / Write
SEQ1MQ8T1 と傾向は変わりません。Read 179 ~ 188 MB/sec、Write 177 ~ 183 MB/sec でした。


RND4KQ32T1 Read / Write
機種間の差は SEQ1M の場合と逆で、SG が低め、WD が高めの傾向でした。
Read では、filesystem 間の差は殆どありません。Write は、先に記載した通り JFS のアクセス速度が他よりも速い結果でした。


RND4KQ1T1 Read / Write
機種間の差は、Read は殆どありません。Write は SG よりも WD の方が速い結果でした。
filesystem の違いは RND4KQ32T1 と傾向は変わりません。


【まとめ】できるだけ Cache を使用しない条件
できるだけ Cache を使用しない条件でアクセス速度を測定した結果をまとめました。
- 機種間のアクセス速度の違いが若干存在していました。SEQ1M は SG が速め、RND4K は WD が速め。
- SEQ1M Read / Write は filesystem による違いは殆どありませんでした。
- RND4K Read は filesystem による明確な差はありませんでした。
- RND4K Write は JFS のアクセス速度のみ極端に速く、それ以外は横並びでした。
始めに予想した通り、Cache を使用しない場合には、ディスク自体のアクセス速度が律速となり、filesystem による違いはあまり見られませんでした。
RND4K の JFS の Write のアクセス速度が速い理由は分かりませんでした。
fio の測定結果 2 : Cache を最大限に使用した条件
Linux では PC のメインメモリを積極的にディスクの Cache として使用します。Read も Write も Cache を間に挟み平準化する事で、全体としては本来のディスクの性能以上のアクセス速度を達成させています。Read / Write が間欠的に発生するような状況では、Cache を使用した高速なアクセス速度が見かけ上は得られます。
- Read の場合は読み込んだファイルがメモリ上に残り、2回目の読み込みの際にはディスクへのアクセスなしでメモリからファイルの内容が渡される。
- Write の場合は書き込み内容を一旦メモリに溜めておき、一定の条件下でディスクにまとめて書き込む。
Read の場合、一旦 /dev/null に cat で書き込むと Cache に記録されるので、その後で読み込む事で Cache がフルに効果を発現する状況を作りました。
Write で書き込みを行う場合には、Dirty cache に溜められて遅延書き込みされます。今回は、Cache に書き込まれる時間だけでなく、遅延書き込みに要する時間も同時に調べてみました。思いのほか時間を要する事もありました。
その為、Dirty cache が現時点でどの位使用されているか、最終的に sync が完了したかを調べる方法が必要でしたので、以下のページを参考にワンライナーで監視しました。
%22%20transform%3D%22translate(.5%20.5)%22%20fill-opacity%3D%22.5%22%3E%3Cellipse%20fill%3D%22%23003b85%22%20rx%3D%221%22%20ry%3D%221%22%20transform%3D%22rotate(-179.6%2036%20-.1)%20scale(159%2017.63934)%22%2F%3E%3Cellipse%20fill%3D%22%23fff7ef%22%20rx%3D%221%22%20ry%3D%221%22%20transform%3D%22matrix(-119.95855%204.81803%20-1.2866%20-32.03332%2059.3%2063.2)%22%2F%3E%3Cellipse%20fill%3D%22%23938991%22%20rx%3D%221%22%20ry%3D%221%22%20transform%3D%22matrix(-129.21227%20.45104%20-.01561%20-4.47306%2080.2%2020.3)%22%2F%3E%3Cellipse%20fill%3D%22%230a5989%22%20cx%3D%2284%22%20cy%3D%223%22%20rx%3D%22159%22%20ry%3D%225%22%2F%3E%3C%2Fg%3E%3C%2Fsvg%3E)
$ while true; do sleep 1; cat /proc/{vmstat,meminfo} | egrep "^nr_dirty|^nr_writeback" | awk 'BEGIN{print strftime("%H:%M:%S\t")}{print $2 "\t"}' | tr -d "\n"; echo ""; done
18:04:43 0 0 0 206553 103150
18:04:44 0 0 0 206530 103139
18:04:45 0 0 0 206531 103139
各列の意味は上記リンク先に記載があります。着目するのは、2列目の Dirty cache に使われているページ数、3列目の Writeback で書き込まれたページ数の部分です。徐々に Dirty cache が減少する事が分かります。
Dirty cache を確認するもう一つの方法を以下のページで見つけました。

$ watch grep -e Dirty: -e Writeback: /proc/meminfo
実行例は以下の通りです。
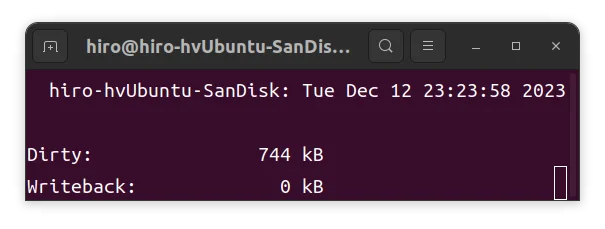
こちらはページ数ではなく kB で表示されます。
この2種類の方法を併用して、Dirty cache の量を把握し、sync が確実に完了した事を確認しながらアクセス速度を測定しました。
測定不具合の状況と対処 (JFS)
RND4K Cache Write の後の sync に異常に時間を要する
Ext2、XFS、Btrfs では問題なく測定できたのですが、JFS のみ、以下のような状況が発生しました。
- SEQ1M の条件では他の filesystem と同様に測定できて問題なし。
- RND4K の Read の条件も同じく問題なし。
- RND4K の Write のみ、書き込んだ後の sync に異常に時間を要する。
| 条件 RND4K | RND4KQ32T1 | Write [MB/sec] | sync [sec] |
| Q32T1 | SG | 1378.45 | 2262.0 |
| Q32T1 | WD1 | 1376.03 | 1769.4 |
| Q32T1 | WD2 | 1383.66 | 1814.5 |
| Q1T1 | SG | 1431.75 | 2263.3 |
| Q1T1 | WD1 | 1452.33 | 1751.6 |
| Q1T1 | WD2 | 1451.33 | 1787.2 |
他の filesystem では、同じ条件で sync に要する時間は 17 ~ 20秒程度でした。それに対して、JFS では最小1751 sec (27m31s)、最大2263 sec (37m43s) と 30分程度を要しました。
対策 : sync せずに測定し最後にデータファイルを消去
この原因を調査する為に、Dirty cache や Writeback の量の変化を見ながら色々と試してみました。
- sysctl コマンドや /sys/block/sd[abc]/ 以下のパラメータを変更し、pdflush による Writeback が早めに動作するように調整
- Multi-queue I/O scheduler の変更。default の mq-deadline から bfq や kyber へ変更
%22%20transform%3D%22translate(.5%20.5)%22%20fill-opacity%3D%22.5%22%3E%3Cellipse%20fill%3D%22%23003b85%22%20rx%3D%221%22%20ry%3D%221%22%20transform%3D%22rotate(89%2050.3%2051.2)%20scale(17.53917%20158.99999)%22%2F%3E%3Cellipse%20fill%3D%22%23fff8ef%22%20rx%3D%221%22%20ry%3D%221%22%20transform%3D%22matrix(114.4101%20-9.1959%202.6536%2033.01443%2060.5%2064.2)%22%2F%3E%3Cellipse%20fill%3D%22%23978988%22%20cx%3D%22102%22%20cy%3D%2220%22%20rx%3D%22128%22%20ry%3D%225%22%2F%3E%3Cellipse%20fill%3D%22%230a5989%22%20cx%3D%2282%22%20cy%3D%223%22%20rx%3D%22142%22%20ry%3D%225%22%2F%3E%3C%2Fg%3E%3C%2Fsvg%3E)
勉強にはなりましたが、これらの対処では sync の時間を短縮させる事は出来ませんでした。
最終的に分かった事は「データファイルを削除」した瞬間に Dirty cache が全てなくなるという事です (当たり前といえばそうですが)。
という事で、
- JFS
- RND4KQ32T1 & RND4KQ1T1
- Write
- Cache
の条件で測定する場合のみ、
- アクセス速度の測定後の sync に要する時間を測定しない
- 測定終了後にデータファイルを削除
という例外の処理を script に追加しています。これで Cache 有効なアクセス速度が測定できるようになりました。
CDM 相当の条件での測定経過 (Cache)
JFS のみ前記の対処を行い、Cache 有効で CrystalDiskMark 相当の条件でディスクのアクセス速度を測定しました。結果について以下にグラフで示します。
特に記載のない場合には N=10 の平均値です。
SEQ1MQ8T1 Read / Write
filesystem の特徴が出ているように思います。
- Read は XFS が他の filesystem と比較してアクセス速度が速い結果でした。他の 3つは横並びでした。
- Write は Btrfs が最も早く、XFS、JFS、Ext4 の順にアクセス速度が下がりました。


SEQ1MQ1T1 Read / Write
SEQ1MQ8T1 と同傾向です。


RND4KQ32T1 Read / Write
RND4K でも filesystem の差が出ています。
- Read は XFS のみアクセス速度が低め。他の3つは同等
- Write は JFS、Ext4、XFS、Btrfs の順にアクセス速度が下がる


RND4KQ1T1 Read / Write
RND4KQ32T1 と同じ傾向です。


【まとめ】Cache を最大限に使用した条件
Cache を最大限に使用した条件でアクセス速度を測定した結果をまとめました。
- filesystem による違いが明確に見られました。
- SEQ1M Read は XFS が他の filesystem と比較してアクセス速度が速い結果でした。他の 3つは横並びでした。
- SEQ1M Write は Btrfs が最も早く、XFS、JFS、Ext4 の順にアクセス速度が下がりました。
- RND4K Read は XFS のみアクセス速度が低めで、他の3つは同等でした。
- RND4K Write は JFS が最もアクセス速度が速く、Ext4、XFS、Btrfs の順に下がりました。
アクセス速度の filesystem による違いを一覧表にしました。(1:速い -> 4:遅い)
| Filesystem | SEQ1M Read | SEQ1M Write | RND4K Read | RND4K Write |
| Ext4 | 2 | 4 | 1 | 2 |
| XFS | 1 | 2 | 2 | 3 |
| Btrfs | 2 | 1 | 1 | 4 |
| JFS | 2 | 3 | 1 | 1 |
今回の傾向から、XFS と Btrfs は比較的大きなファイル向き、JFS は比較的小さなファイル向き、Ext4 は大きなファイルの書き込みはイマイチで他は中間の性能、という事が分かりました。
他の測定方法による結果
hdparm、dd、及び約 8 GiB (449,077 files) のファイルのコピーについてもアクセス速度を測定しました。
hdparm
hdparm は filesystem 非依存の測定方法です。Cache 無し (-t) と、測定していなかった Cache 有り (-T) の結果を測定しました。
| hdparm -t | SG | WD1 | WD2 |
| Read [MB/sec] | 177.9 | 176.1 | 178.1 |
| R / Avg. [%] | 1.5 | 3.4 | 3.2 |
| hdparm -T | SG | WD1 | WD2 |
| Read [MB/sec] | 11,931.6 | 11,778.5 | 118,53.5 |
| R / Avg. [%] | 3.7 | 2.8 | 4.9 |
何方もバラツキは少なく、Cache 有りの場合は約 67倍のアクセス速度となりました。
dd
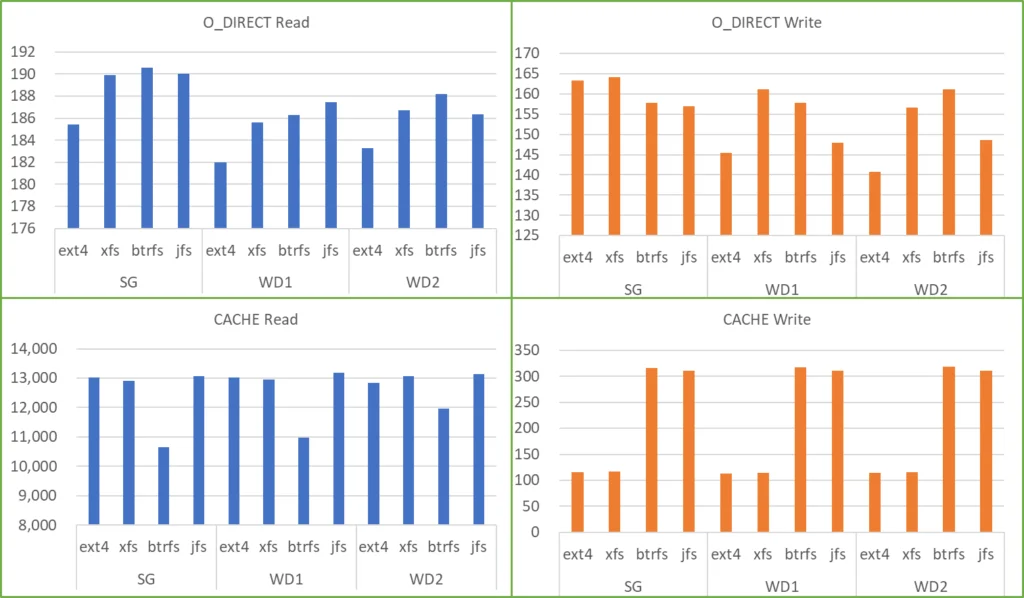
dd も O_DIRECT (Cache 無し) と Cache 有りで測定しました。結果をグラフで示します。
- Cache 無しの場合は Read 182 ~ 191 MB/sec、Write は 141 ~ 164 MB/sec の結果でした。
- filesystem の違いは、O_DIRECT Read では WD1 を除き Btrfs が最も早く、次いで XFS と JFS が同等、Ext4 が最も遅い結果でした。
- O_DIRECT Write では HDD の機種により傾向が変わり、明確な違いがみられませんでした。アクセス速度のバラツキも大きく、dd で測定するのは難しいと感じました。
- Cache 有りの場合は Read 10,654 ~ 13,186 MB/sec、Write は 113 ~ 318 MB/sec の結果でした。
- Cache Read では Btrfs が低め、他は横並びの結果でした。
- Cache Write では Ext4 と XFS が低め、Btrfs と JFS は高めでした。
全体としては、fio の SEQ1M の結果とは異なる傾向でしたので、dd の結果のみをアクセス速度の評価に使用するのは難しいと感じました。
8.3 GiB のファイルのコピー
実際の使用条件を模したテストとして、8.3 GiB (ファイル数449077、平均 19.5 kiB) のファイルを SATA SSD から HDD に cp するのに要した時間とアクセス速度を測定しました。
Sequential と Random アクセスの、どちらかといえば Random アクセスに近い Write の条件になります。
測定前には Cache を消去して 1回目の測定を行い、2回目はキャッシュを消さずに測定しています。
$ du -sk external
8753948 external
$ find external | wc -l
449077
# clear Cache
$ sync
$ sudo sh -c "echo 3 > /proc/sys/vm/drop_caches"
# measure (1st)
$ /usr/bin/time -f %e cp -pr external /media/hiro/SG/; /usr/bin/time -f %e sync
$ rm -fr /media/hiro/SG/external
$ sync
# measure (2nd)
$ /usr/bin/time -f %e cp -pr external /media/hiro/SG/; /usr/bin/time -f %e sync結果のグラフを以下に示します。
アクセス速度は、Cache にデータが入る事により、1回目よりも2回目の方が速くなります。ただ、Ext4、XFS、Btrfs は約5倍に上昇するのに対して、JFS は 1.2 ~ 1.3 倍と上昇幅が少ない状態でした。fio の RND4K Cache の結果では、JFS は他の filesystem と比べて劣る事はありませんでしたので不思議な結果です。


書き込み終了後の Sync time は、Ext4、XFS、Btrfs は1回目よりも2回目の方が長くなっています。
- 1回目は Cache メモリの確保と書き込み、ディスクへの書き込みが平行して行われていて、アクセス速度が低くなる代わりに Sync time が短い
- 2回目は Cache メモリが既に存在しているので、Cache メモリの確保が不要、書き込みがメモリに対して行われるのでアクセス速度は高くなり、遅延書き込みが sync により強制的に行われるので Sync time は長くなる
という状況だと推測します。
JFS のみ、1回目と2回目でほぼ変化がありません。Cache をあまり使えていない状況のようです。mount の際の sync option は外しているのですが。

ディスクへの書き込み + Sync time を合計した、ディスクに完全に書き込みが終了するまでの時間である Total Time については、Cache の効果により1回目よりも2回目の方が短くなっていました。
1回目は Ext4、XFS、Btrfs が横並び ~ XFS が少し長め、JFS が他よりも長い結果でした。
1回目に対して2回目は 0.52 ~ 0.82 倍となりました。Btrfs が 0.52 ~ 0.53 倍と Cache を有効に活用且つ効率的にディスクに書き込んでおり、次いで Ext4 が 0.67 ~ 0.69、XFS が 0.71 ~ 0.75、JFS が最も時間を要していて 0.77 ~ 0.82 となりました。Btrfs が最も Cache を有効に利用できていて、逆に JFS が Cache をあまり有効に利用できていないようです。
アクセス速度で見ると Btrfs は他の filesystem と比較して大差なく、RND4K の書き込みでは劣る傾向が見られましたが、最終的にディスクへの書き込みが終了するまでの時間を考えると、Cache にデータが入っている条件では Btrfs が最も少ない時間で終了しています。


今回はアクセス速度の測定が終了した直後に強制的に sync で書き込んで時間を測定しました。実運用上は、Dirty Cache は一定の条件下で遅延書き込みされますので、負荷が低めの環境ではアクセス速度にのみ着目して、Sync time の影響は考えなくても良いのかもしれません。
とはいえ、突然の電源断などのトラブルを想定すれば、Dirty Cache がディスクに実際に書き込まれるまでの時間が短い方がデータ喪失のリスクが下がります。このような観点では、Dirty Cache から効率的にディスクに書き込まれる filesystem の方が安全だと思います。
まとめ
今回の記事では、3種類の HDD (SG, WD1, WD2) を Ext4、XFS、Btrfs、JFS の 4種類の filesystem でフォーマットし、Linux の fio を使用してディスクのアクセス速度を測定して比較しました。測定の際に不具合のような状況が幾つか発生しましたので、その対処についても記載しました。
できるだけ Cache を使用しない条件のアクセス速度
基本的には fio で direct を有効にすると、O_DIRECT が有効になり、Cache を使用しない測定になるはずなのですが、Btrfs と JFS については RND4K で徐々にアクセス速度が上昇する現象が見られました。これについては mount option を変更して対処しました。
- Btrfs … Space cache と CoW (Copy on Write) を無効にする option を追加
$ sudo mount -t btrfs -o clear_cache,nospace_cache,nodatacow /dev/sda1 /media/hiro/btrfs逆に Space cache と CoW を有効にする場合には、以下の様に mount します。
$ sudo mount -t btrfs -o space_cache=v2 /dev/sda1 /media/hiro/btrfs- JFS … sync option の追加
$ sudo mount -t jfs -o sync /dev/sda1 /media/hiro/jfs元に戻す場合には、sync option を付けなければ OK です。
このような対処をした上で、各 filesystem でアクセス速度を測定しました。結果をまとめると以下の通りです。
- 機種間のアクセス速度の違いが若干存在していました。SEQ1M は SG が速め、RND4K は WD が速め。
- SEQ1M Read / Write、RND4K Read は filesystem による違いは殆どありませんでした。
- RND4K Write は JFS のアクセス速度のみ極端に速く、それ以外は横並びでした。
Cache を使用しない場合には、ディスク自体のアクセス速度が律速となり、filesystem による違いはあまり見られませんでした。RND4K の JFS の Write のアクセス速度が速い理由は分かりませんでした
Cache を最大限に使用した条件のアクセス速度
Cache を最大限に使用した条件でアクセス速度を測定しました。実際の使用状況としては、先に記載した「できるだけ Cache を使用しない条件」と、以下の「Cache を最大限に使用した条件」の間のアクセス速度になると思います。
Cache を使用した際には、filesystem による違いが明確に見られました。一覧表にまとめると以下の様になりました。(1:速い -> 4:遅い)
| Filesystem | SEQ1M Read | SEQ1M Write | RND4K Read | RND4K Write |
| Ext4 | 2 | 4 | 1 | 2 |
| XFS | 1 | 2 | 2 | 3 |
| Btrfs | 2 | 1 | 1 | 4 |
| JFS | 2 | 3 | 1 | 1 |
今回の傾向から、XFS と Btrfs は比較的大きなファイル向き、JFS は比較的小さなファイル向き、Ext4 は大きなファイルの書き込みはイマイチで他は中間の性能、という事が分かりました。(JFS については、次項の結果から小さなファイル向きという結論にはなりませんでした)
他の測定方法による結果
hdparm と dd、8.3 GiB のファイル書き込みの3種類についてアクセス速度を測定しました。
- hdparm では Cache の有無で Sequential Read で約67倍のアクセス速度の差がありました。(hdparm による測定は filesystem は影響しませんので参考値です)
- dd では機種による傾向の違いがあり、filesystem の影響は判別できませんでした。
8.3 GiB (ファイル数449077、平均 19.5 kiB) のファイルを SATA SSD から HDD に cp するのに要した時間とアクセス速度を測定しました。1回目は Cache を消して書き込み、2回目は Cache を利用して書き込む方法で試しました。書き込み終了後に sync でディスクに全て書き込む時間も測定しました。
アクセス速度に関しては、以下のような結果でした。
- アクセス速度は、Cache にデータが入る事により、1回目よりも2回目の方が速くなりました。
- ただ、Ext4、XFS、Btrfs は約5倍に上昇するのに対して、JFS は 1.2 ~ 1.3 倍と上昇幅が少ない状態でした。
- fio の RND4K Cache の結果では、JFS は他の filesystem と比べて劣る事はありませんでしたので不思議な結果です。
ディスクへの書き込み + Sync time を合計した、ディスクに完全に書き込みが終了するまでの時間である Total time については、Cache の効果により1回目よりも2回目の方が短くなっていました。
- 1回目は Ext4、XFS、Btrfs が横並び ~ XFS が少し長め、JFS が他よりも長い結果でした。
- 1回目と2回目の Total time の比は、Btrfs が 0.52 ~ 0.53 倍と Cache を有効に活用且つ効率的にディスクに書き込んでおり、次いで Ext4、XFS、JFS の順でした。
- Btrfs が最も Cache を有効に利用できていて、逆に JFS が Cache をあまり有効に利用できていないようです。
8.3 GiB の書き込みのアクセス速度で見ると、Btrfs は他の filesystem と比較して大差なく、RND4K の書き込みでは劣る傾向が見られましたが、最終的にディスクへの書き込みが終了するまでの時間を考えると、Btrfs が最も少ない時間で終了しています。
私なりの結論
今回、4種類の filesystem (Ext4, XFS, Btrfs, JFS) をアクセス速度に焦点を当てて比較しました。
私なりの結論をまとめます。
- Ext4 : Linux の defact standard な filesystem だけあって、可もなく不可もなく平均的なアクセス速度だと感じました。filesystem の種類に拘りが無い、あるいはどの filesystem を使用するか迷う場合には、よほど特殊な用途でなければ、Ext4 を選んでおけば十分な性能を発揮できると思います。ただ、未だに "lost+found" が filesystem の root に残っているのは旧時代的だなぁと感じます。
- XFS : 使い勝手としては Ext4 と変わらず、Ext4 と比較して SEQ1Mは速い、RND4K は遅い、8.3 GiB の書き込みは遅い、という事で大きなファイルの扱いに向いている印象です。XFS 独自の RAID0 時のスループット向上は未だ試せていないので、md5adm + LVM と組み合わせた場合にどうなるか楽しみです。
- Btrfs : SEQ1M の書き込みが速く、RND4K の書き込みが遅いという結果でした。とはいえ、Btrfs の目指している所はアクセス速度の向上ではなく、「耐障害性、修復性、容易な管理」だと思います。この先、Storage pool や RAID を構築する事を通じて、この点を確認しつつアクセス速度についても調べたいと考えています。また、スナップショット等の機能も試していませんので、こちらについても今度試してみたいと思います。
- JFS : IBM の AIX が元になっていますが、Linux 版は (個人的な意見ですが) 機能限定版のような気がします。fio の RND4K のアクセス速度は速い結果でしたが、8.3 GiB の書き込みでは上手く Cache を使い切れていないような印象でした。今回は試しませんでしたが、別の I/O scheduler との組み合わせる等、別の最適化の方法があるのかもしれません。
以上より、現時点での私の filesystem の選択の優先順位は、Ext4 = XFS >= Btrfs > JFS です。
今回の結果から JFS を除外し、ZFS を加えて、Storage pool や RAID 機能について試してみたいと考えています。
今回のアイキャッチ画像
黒猫を SDXL で生成しました。黒猫と三毛猫は昔から憧れです。でも猫との相性は良くないのが残念です。
HDD には byte 単価はかないませんが、SATA SSD の 4TB も手の届く金額になりました。SATA SSD を使った自作 NAS にもチャレンジしてみたい所です。Crucial MX500 の 500GB はサブマシンの Minisforum GK41 で Linux 用に使用しています。























コメント