
はじめに
Synology の DS218plus の HDD を 4TB -> 8TB に更新した際に、内蔵2基 + Hyper Backup 用1基の合計3基 (SG, WD1, WD2) の 4TB HDD が遊休となりました。これらの HDD を使用して、Linux の様々なファイルシステムの違いや Software RAID を組んだ場合のディスクのアクセス速度を測定しようと考えています。

前回の記事「その4【各filesystem測定編】」では、Linux で fio を使用して、Ext4 / XFS / Btrfs / JFS のディスクのアクセス速度を測定してみました。

Cache の無効 / 有効の条件で測定しました。
その結果、
- Cache を使用しない条件では、多少のバラツキはあるものの、ディスク自体のアクセス速度が律速となり、filesystem による違いは見られませんでした。
- Cache を使用する条件では、filesystem による向き・不向きが見られました。Ext4 は平均的、XFS と Btrfs は比較的大きなファイルを扱う場合にアクセス速度が向上しました。
- 小さいファイルの扱いは Btrfs は苦手のようですが、Btrfs が目指しているのは「耐障害性、修復性、容易な管理」であり、ディスクのアクセス速度については優先順位が高くないと思います。
- JFS は (個人的な意見ですが) Linux 版は機能限定版のような印象でした。
という事が分かりました。現時点での私の filesystem の選択の優先順位は、Ext4 = XFS >= Btrfs > JFS です。JFS は今回から評価対象から除外します。
今回は mdadm を使用して、RAID 0 (2基、3基) / RAID 1 / RAID 5 の RAID を構成し、それぞれ Ext4 / XFS / Btrfs でフォーマットしてディスクのアクセス速度を測定しました。RAID を使用しない場合と比較し、RAID の効果について調べました。
mdadm と RAID について
mdadm と RAID について簡単に説明します。
mdadm について


mdadm is a Linux utility used to manage and monitor software RAID devices. It is used in modern Linux distributions.
mdadmは、最近のLinuxディストリビューションで使用されている、ソフトウェアRAIDデバイスの管理と監視に使用されるLinuxユーティリティです。
https://en.wikipedia.org/wiki/Mdadm
mdadm (Multiple Disk and Device Management の略称) は、Software RAID を作成・管理・監視する為のソフトウェアです。複数の記憶媒体 (HDD や SSD) をアレイ (array, 一括り) にまとめて、一つの block device として扱えるようにします。
mdadm が対応する RAID レベルについて
mdadm は世の中に存在する殆どの RAID レベルに対応できます。
一般的な RAID レベルとしては、次の4項目です。
- RAID 0 ... 2基以上の記憶媒体に分散してデータを記録 (ストライピング、striping)
- RAID 1 ... 2基の記憶媒体に同じ内容を記録 (ミラーリング、mirroring)
- RAID 5 ... 3基以上の記憶媒体にデータとパリティを分散して記録
- RAID 6 ... 4基以上の記憶媒体にデータとパリティを分散して記録
オリジナルのデータと、パリティと呼ばれる冗長コードを分散して記録する事により、アクセス速度、冗長性、又はその両方を向上させるのが RAID の機能となります。
基本的には、同じ容量の記憶媒体を使用します。容量の異なる記憶媒体を使用する場合には、最も少ない容量の記憶媒体に合わせて領域を確保します。
| RAID レベル | 目的 | 冗長性 | 記憶媒体 の数 (n) | メリット | デメリット |
| RAID 0 (striping) | アクセス速度向上 | なし | 2~ | 構成する記憶 媒体の台数 n が増加すると アクセス速度が 向上する n基の合計の 容量を使用できる | 記憶媒体1基の 故障により RAID アレイ 全体の データが消失 |
| RAID 1 (mirroring) | 冗長性の担保 | あり (1台まで) | 2~ | 記憶媒体が1基 故障しても 継続して使用 できる。 | 記憶媒体の 総容量の半分 しか使用 できない |
| RAID 5 (striping + mirroring) | アクセス速度向上 + 冗長性の担保 | あり (1台まで) | 3~ | アクセス速度の 向上と冗長性を 両立できる 記憶媒体の (n-1) 基分の 容量を使用できる | パリティの 計算が必要 なのでCPU 負荷が増加 |
| RAID 6 (striping + mirroring) | アクセス速度向上 + 冗長性の担保 | あり (2台まで) | 4~ | アクセス速度の 向上と冗長性を 両立できる 記憶媒体の (n-2) 基分の 容量を使用できる 冗長性が RAID 5 よりも向上 | パリティの 計算が必要 なのでCPU 負荷が増加 |
RAID 0 (striping) は冗長性 (じょうちょうせい、Redundancy、余剰・重複)が無く、記憶媒体が1基でも故障すると RAID 0 アレイ全体のデータが失われます。
RAID 1 (mirroring) の場合は2基の記憶媒体に同じ内容が記録されますので、記憶媒体の片方が故障しても、もう1基で運用しながら故障した記憶媒体を交換し、RAID 1 アレイを再構成する事によって復旧できます。
RAID 5、RAID 6 はデータとパリティを複数の記憶媒体に分散して記録します。その為、RAID 5 の場合は1基、RAID 6 の場合は2基の記憶媒体が故障しても、記憶媒体を交換して RAID アレイを再構築すれば復旧する事が出来ます。
RAID 1 / 5 / 6 の場合は、予備 (スタンバイ) の記憶媒体を追加できます。記憶媒体の故障時に予備の記憶媒体をアレイに組み込んで RAID を再構成する事ができます。
他にも、ネストされた RAID レベルとして
- RAID 1+0 ... RAID 1 で構成した array を RAID 0 に組み合わせて記録
- RAID 10 ... Linux 独自の RAID レベルで、パリティーなしで分散記録
もあります。RAID の説明で分かりやすいのは Arch Linux Wiki の RAID のページです。

Arch Linux Wiki は有用な情報が多いです。
block size, chunk, stride, stripe width
striping を含む RAID0 / 5 / 6 の場合には、
- chunk (チャンク)
- stride (ストライド) ... XFS では stripe と記載されている
- stripe width (ストライプ幅)
の3つを適切に設定する事によって、RAID の記憶領域の効率的な使用やアクセス速度の向上が期待できます。(RAID 1 の場合は影響しません)
- block size は filesystem の最小の読み書き単位で通常は 4kiB です。
- chunk は striping で分割して書き込む最小単位です。mdadm の default では 512 kiB に設定されます。striping の効果を向上させる為には、大きなファイルを扱う場合には小さく (なるべく複数の記憶媒体に分散されるように)、小さいファイルを扱う場合には大きく (一度に複数のファイルを読み込むように) 設定します。
- stride と stripe width は、chunk size とデータが記録される記憶媒体の数によって決められる値です。以下の式で求めます。
- stride = (chunk size / block size)
- stripe width = (data block device num * stride)
例を挙げます。
| RAID level | number of disks | block size [kiB] | chunk size kiB | stride blocks | stripe width blocks | 備考 |
| RAID 0 | 2 | 4 | 512 | 128 (512/4) | 256 (2*128) | 記録する disk は 2基 |
| RAID 0 | 3 | 4 | 512 | 128 (512/4) | 384 (3*128) | 記録する disk は 3基 |
| RAID 5 | 3 | 4 | 512 | 128 (512/4) | 256 (2*128) | 記録する disk は (3-1) = 2基 |
| RAID 6 | 4 | 4 | 512 | 128 (512/4) | 256 (2*128) | 記録する disk は (4-2) = 2基 |
実際には、mkfs.ext4 や mkfs.xfs では、block size と chunk size を元に上記の stride と stripe width を適切に設定してくれますので、chunk size を変更した場合等に注意する程度で大丈夫かと思います。
ディスクのアクセス速度に影響するのは chunk size だと思います。今回は default の 512 kiB で測定しました。この先、chunk size の条件を変えて測定してみようと考えています。
RAID はバックアップではない
勘違いされている方が多いですが、RAID はバックアップではありません。冗長化されている RAID 1 / 5 / 6 は PC / NAS 等が停止するリスクを下げる事が目的であり、データの喪失を完全に防止する事は出来ません。間違って消したファイルは元には戻せません。
データの喪失を防止する為には、RAID と定期的なバックアップ、できれば多重バックアップが必要です。
- NAS で RAID でネットワークドライブを使用
- 外付 HDD へ定期・自動的にバックアップ
- 物理的に別の場所、又はクラウドに定期・自動的にバックアップ
のような形で、RAID に記録されているデータの重要性に応じて、バックアップの頻度を決め、多重化する事が必要です。
最近の NAS には上に挙げた機能が含まれていますので、データの保管場所として使用するだけでなく、手間を要しないバックアップを実現できます。
mdadm による RAID array の作成方法
mdadm による RAID array の作成方法について説明します。今回も 3基の HDD (Seagate IronWolf 4TB: SG, WesternDigital Red 4TB : WD1, WD2) を使用します。HDD が 3基ですので、
- RAID 0 ... 2基
- RAID 0 ... 3基
- RAID 1 ... 2基
- RAID 5 ... 3基
の 4種類について RAID array を作成します。
お約束ですが重要な事ですので記載します。
以下、各 HDD と block device の関係は表に示した内容を前提として説明します。
| HDD | 略称 | block device |
| Seagate IronWolf 4TB | SG | /dev/sda |
| WesternDigital Red 4TB (1) | WD1 | /dev/sdb |
| WesternDigital Red 4TB (2) | WD2 | /dev/sdc |
HDD の RAID 情報の削除
一度でも HDD を RAID で使用した場合には、パーティションに RAID の情報が記録されている為に、新たに RAID array を組む事が出来なくなります。RAID アレイに組み込む HDD の RAID の情報を消去します。
$ sudo mdadm --misc --zero-superblock /dev/sda1 /dev/sdb1 /dev/sdc1何も文字が出力されなかった場合には、正常に RAID 情報の消去が済んでいます。
RAID の情報が記録されていない場合には、以下のメッセージが表示されますが問題ありません。
$ sudo mdadm --misc --zero-superblock /dev/sda1 /dev/sdb1 /dev/sdc1
mdadm: Unrecognised md component device - /dev/sda1
mdadm: Unrecognised md component device - /dev/sdb1
mdadm: Unrecognised md component device - /dev/sdc1gdisk で HDD のパーティションの作成
3基の HDD の容量は 4TB ですので GPT 形式でパーティションを作成します。gdisk を使用します。
もしインストールされていない場合には、Ubuntu / Debian であれば apt でインストールします。
$ sudo apt install gdisk注意点としては以下の通りです。
- メーカーの異なる HDD が完全に同容量とは限らないので、最後に 100 MiB 以上の空きを作る事が Arch Linux Wiki の RAID のページで推奨されています。今回の HDD は 4 TB = 3.64 TiB = 3727 GiB ですので、3725 GiB を割り当てました。(空きが 1 GiB です)
- パーティションのタイプに HEX code 'FD00' (Linux RAID) を指定します。(通常のファイルシステムの場合は HEX code '8300' (Linux Filesystem) を指定します)
/dev/sdc に gdisk でパーティションを作成する例を示します。(長いのでアコーディオンにします。クリックで開きます)
# 赤字は入力部分 緑字はコメント
$ sudo gdisk /dev/sdc
GPT fdisk (gdisk) version 1.0.8
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT.
Command (? for help): p # パーティション情報の表示
Disk /dev/sdc: 7814037168 sectors, 3.6 TiB
Model: WD40EFRX-68N32N0
Sector size (logical/physical): 512/4096 bytes
Disk identifier (GUID):
ABCDEFGH-1234-IJKL-5678-MNOPQRSTUVWX
Partition table holds up to 128 entries
Main partition table begins at sector 2 and ends at sector 33
First usable sector is 34, last usable sector is 7814037134
Partitions will be aligned on 2048-sector boundaries
Total free space is 7814037101 sectors (3.6 TiB)
Number Start (sector) End (sector) Size Code Name
Command (? for help): n # 新しくパーティションを作成
Partition number (1-128, default 1): 1 # 1番目のパーティション
First sector (34-7814037134, default = 2048) or {+-}size{KMGTP}: 2048 # 最初の sector (default)
Last sector (2048-7814037134, default = 7814037134) or {+-}size{KMGTP}: +3725G # 割り当てる量を GiB で指定
Current type is 8300 (Linux filesystem)
Hex code or GUID (L to show codes, Enter = 8300): FD00 # FD00 'Linux RAID' を指定
Changed type of partition to 'Linux RAID'
Command (? for help): p # 最終確認
Disk /dev/sdc: 7814037168 sectors, 3.6 TiB
Model: WD40EFRX-68N32N0
Sector size (logical/physical): 512/4096 bytes
Disk identifier (GUID): 3FFDEA3C-8F66-42E7-83FF-C1A54A0DC7DD
Partition table holds up to 128 entries
Main partition table begins at sector 2 and ends at sector 33
First usable sector is 34, last usable sector is 7814037134
Partitions will be aligned on 2048-sector boundaries
Total free space is 2145901 sectors (1.0 GiB) # 未割当の残りの容量
Number Start (sector) End (sector) Size Code Name
1 2048 7811893247 3.6 TiB FD00 Linux RAID
Command (? for help): w # パーティション情報の書込み
Final checks complete. About to write GPT data. THIS WILL OVERWRITE EXISTING
PARTITIONS!!
Do you want to proceed? (Y/N): y # 最終確認、書き込むなら 'y'
OK; writing new GUID partition table (GPT) to /dev/sdc.
The operation has completed successfully./dev/sda、/dev/sdb についても同様にパーティションを作成します。
mdadm で RAID array を作成
/dev/sd[abc]1 のパーティションを作成できたら、これらを使用して mdadm で RAID array を作成します。作成後には、'cat /proc/mdstat' で RAID の状態を確認できます。
'/dev/md0' として RAID array が使用できるようになります。
$ sudo mdadm --create /dev/md0 --verbose --chunk=512K \
--level=0 --raid-devices=2 /dev/sdb1 /dev/sdc1
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
$ cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4] [linear] [multipath] [raid0] [raid1] [raid10]
md0 : active raid0 sdc1[1] sdb1[0]
7811627008 blocks super 1.2 512k chunks
unused devices: <none>$ sudo mdadm --create /dev/md0 --verbose --chunk=512K \
--level=0 --raid-devices=3 /dev/sda1 /dev/sdb1 /dev/sdc1
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
$ cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4] [linear] [multipath] [raid0] [raid1] [raid10]
md0 : active raid0 sdc1[2] sdb1[1] sda1[0]
11717440512 blocks super 1.2 512k chunks
unused devices: <none>RAID 0 は stripe ですので、再同期 (resync) はありません。作成して直ぐに使用できます。
$ sudo mdadm --create /dev/md0 --verbose \
--level=1 --raid-devices=2 /dev/sdb1 /dev/sdc1
mdadm: Note: this array has metadata at the start and
may not be suitable as a boot device. If you plan to
store '/boot' on this device please ensure that
your boot-loader understands md/v1.x metadata, or use
--metadata=0.90
mdadm: size set to 3905813504K
mdadm: automatically enabling write-intent bitmap on large array
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
# 作成直後
$ cat /proc/mdstat
Personalities : [raid0] [linear] [multipath] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid1 sdc1[1] sdb1[0]
3764255744 blocks super 1.2 [2/2] [UU]
[>....................] resync = 0.0% (1328576/3764255744) finish=330.4min speed=189796K/sec
bitmap: 29/29 pages [116KB], 65536KB chunk
unused devices: <none>
# resync 終了後
$ cat /proc/mdstat
Personalities : [raid0] [linear] [multipath] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid1 sdc1[1] sdb1[0]
3764255744 blocks super 1.2 [2/2] [UU]
bitmap: 2/29 pages [8KB], 65536KB chunk
unused devices: <none>
RAID 1 では再同期 (resync) が始まりますので、完全に同期するまでに時間を要します。今回の 4 TB の RAID 1 の場合は5.5時間が必要です。stripe の機能はないので chunk size は指定しません。
$ sudo mdadm --create /dev/md0 --verbose --chunk=512K \
--level=5 --raid-devices=3 /dev/sda1 /dev/sdb1 /dev/sdc1
mdadm: layout defaults to left-symmetric
mdadm: layout defaults to left-symmetric
size=3907017540K mtime=Sat Dec 23 19:50:38 2023
mdadm: size set to 3905813504K
mdadm: automatically enabling write-intent bitmap on large array
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
# 作成直後
$ cat /proc/mdstat
Personalities : [raid0] [linear] [multipath] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid5 sdc1[3] sdb1[1] sda1[0]
7528511488 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [UU_]
[>....................] recovery = 0.2% (8311196/3764255744) finish=349.1min speed=179296K/sec
bitmap: 0/29 pages [0KB], 65536KB chunk
unused devices: <none>
# resync 終了後
$ cat /proc/mdstat
Personalities : [raid0] [linear] [multipath] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid5 sdc1[3] sdb1[1] sda1[0]
7528511488 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/3] [UUU]
bitmap: 4/29 pages [16KB], 65536KB chunk
unused devices: <none>
RAID 5 では再同期 (resync) が始まりますので、完全に同期するまでに時間を要します。今回の 4 TB の RAID 5 の場合は約6時間が必要です。
RAID array 情報の記録、再起動時の対策
このまま PC を再起動すると、RAID array の block device が /dev/md0 から /dev/md127 等に変更されてしまいます。これを防止する為に、mdadm の設定ファイルを作成し起動時に反映させるようにします。
mdadm の設定ファイルは /etc/mdadm.conf に書き込む例が多いですが、mdadm の man page を見ると '/etc/mdadm/mdadm.conf.d/' 以下に任意のファイル名で作成すれば読み込まれます。
$ sudo -i
# mkdir -p /etc/mdadm/mdadm.conf.d
# mdadm --detail --scan > /etc/mdadm/mdadm.conf.d/raid5.confupdate-initramfs -u で initrd に反映します。
# update-initramfs -u
update-initramfs: Generating /boot/initrd.img-6.5.0-14-genericこれで、再起動しても RAID array を /dev/md0 で使用する事が出来ます。
mdadm で RAID array を削除
他の用途に使用する場合や RAID 構成を変更する場合等、RAID array を削除する方法です。
# RAID 5 で使用中
$ cat /proc/mdstat
Personalities : [raid0] [linear] [multipath] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid0 sda1[0] sdc1[2] sdb1[1]
11292767232 blocks super 1.2 512k chunks
unused devices: <none>
# RAID array を解除
$ sudo -i
# mdadm --misc --stop /dev/md0
mdadm: stopped /dev/md0
# /dev/md0 が無くなっている事を確認
# cat /proc/mdstat
Personalities : [raid0] [linear] [multipath] [raid1] [raid6] [raid5] [raid4] [raid10]
unused devices: <none>
# 設定ファイルの削除と反映
# rm /etc/mdadm/mdadm.conf.d/raid5.conf
# update-initramfs -u
# パーティションの RAID 情報の削除
$ sudo mdadm --misc --zero-superblock /dev/sda1 /dev/sdb1 /dev/sdc1必要に応じて gdisk でパーティションを削除・再作成します。
各 filesystem でフォーマット
今回は Ext4、XFS、Btrfs の 3種類の filesystem を使用します。各 filesystem のフォーマット方法は以下の通りです。RAID 5 の場合の結果も記載します。
Ext4 では、特に指定しなくても Stride と Stripe width は、chunk と RAID array の構成から適切に設定されました。dumpe2fs の結果も同様です。
$ sudo mkfs.ext4 -F -v /dev/md0
mke2fs 1.46.5 (30-Dec-2021)
...(snip)...
Block size=4096 (log=2)
...(snip)...
Stride=128 blocks, Stripe width=256 blocks
...(snip)...
$ sudo dumpe2fs -h /dev/md0
...(snip)...
Block size: 4096
...(snip)...
RAID stride: 128
RAID stripe width: 256
...(snip)...XFS でも、Ext4 と同様に sunit (Stride)、swidth (Stripe width) が適切に設定されました。man xfs によると、XFS では stride ではなく stripe unit という表記になります。stripe width は Ext4 と変わりません。
$ sudo mkfs.xfs -f /dev/md0
meta-data=/dev/md0 isize=512 agcount=32, agsize=58816384 blks
= sectsz=4096 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1 bigtime=0 inobtcount=0
data = bsize=4096 blocks=1882124288, imaxpct=5
= sunit=128 swidth=256 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=521728, version=2
= sectsz=4096 sunit=1 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
Btrfs は、stride と stripe width の情報が分かりませんでした。man page 内には btrfs で RAID を組んだ場合の情報のみで、mdadm + btrfs の場合に stride と stripe width がどのように設定されるか分かりませんでした。
$ sudo mkfs.btrfs --verbose --force /dev/md0
btrfs-progs v5.16.2
See http://btrfs.wiki.kernel.org for more information.
Performing full device TRIM /dev/md0 (7.01TiB) ...
NOTE: several default settings have changed in version 5.15, please make sure
this does not affect your deployments:
- DUP for metadata (-m dup)
- enabled no-holes (-O no-holes)
- enabled free-space-tree (-R free-space-tree)
Label: (null)
UUID: ABCDEFGH-1234-IJKL-5678-MNOPQRSTUVWX
Node size: 16384
Sector size: 4096
Filesystem size: 7.01TiB
Block group profiles:
Data: single 8.00MiB
Metadata: DUP 1.00GiB
System: DUP 8.00MiB
SSD detected: no
Zoned device: no
Incompat features: extref, skinny-metadata, no-holes
Runtime features: free-space-tree
Checksum: crc32c
Number of devices: 1
Devices:
ID SIZE PATH
1 7.01TiB /dev/md0RAID level とディスクのアクセス速度の関係
これまでの内容を元に、RAID level を変えながらディスクのアクセス速度を測定し、ディスク単体の結果と比較しました。
RAID stripe の chunk size は default の 512 kiB です。
Cache を使用しない場合 (O_DIRECT) と Cache を使用した場合 (CACHE) に分けて測定しました。
Cache を使用しない場合の結果
先ずは Cache を使用しない場合の結果です。
Btrfs の場合は O_DIRECT を有効にしても Cache が効いてしまう事が前回の検証で分かりましたので、mount option を変更しています。
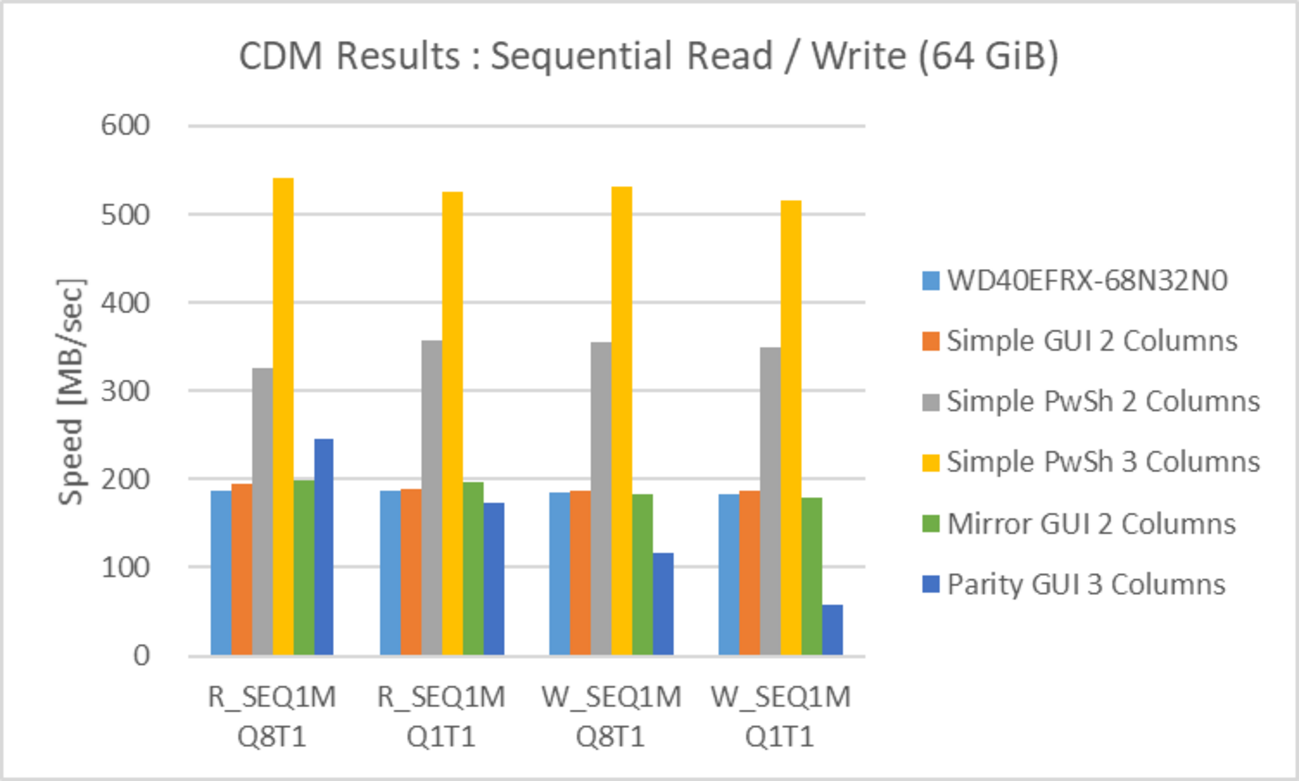
SEQ1MQ8T1
SEQ1M の Read、Write 共に、アクセス速度の速い順に
- RAID 0 (3基)
- RAID 0 (2基)
- RAID 5 (3基)
- 単体、RAID 1 (2基)
という結果でした。
特に 1. RAID 0 (3基) ではアクセス速度が 450 ~ 500 MB/sec に達しており、冗長性には劣るものの、HDD 複数台で SATA SSD と同等のアクセス速度が実現できます。RAID 0 の HDD の数を増やすとリニアにアクセス速度が上昇しており、複数台の striping の効果が明確に出ています。
また、RAID 5 も RAID 0 (2基) と同等~若干落ちるアクセス速度であり、冗長性と HDD 数増によるコスト増を考慮しても、選択肢として有効だと感じます。
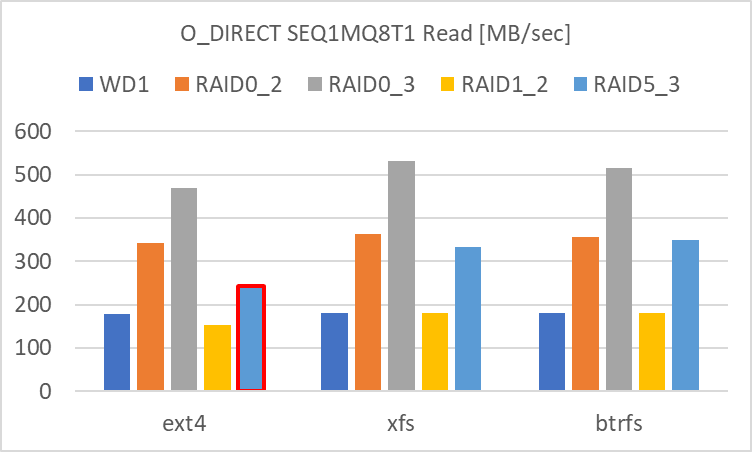
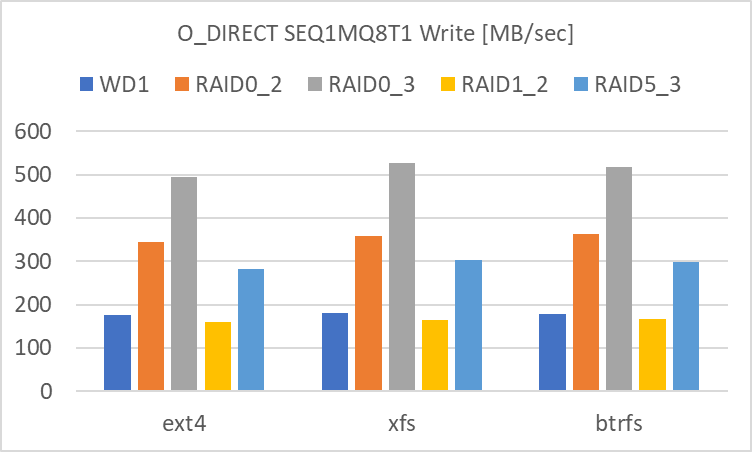
赤枠で囲った部分 (Ext4 Read の RAID 5) に関してはバラツキが大きく、信頼性に欠ける結果です。
SEQ1MQ1T1
SEQ1MQ1T1 でも SEQ1MQ8T1 と同様の結果でした。
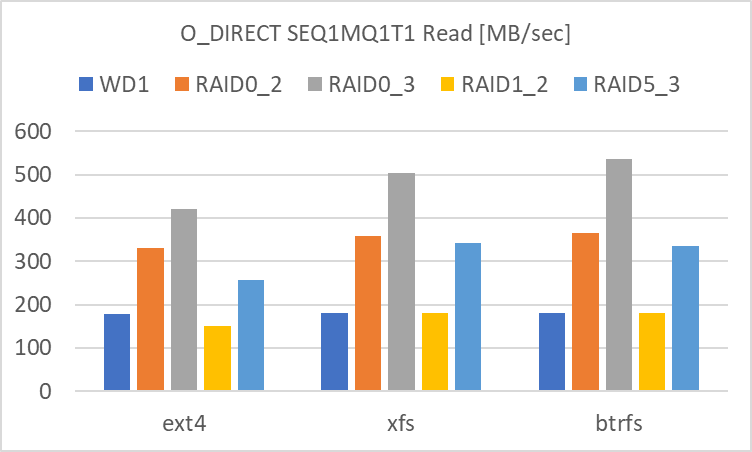
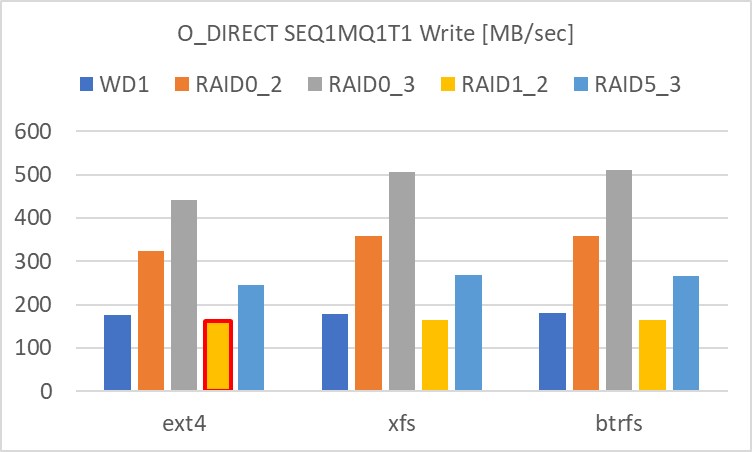
赤枠で囲った部分 (Ext4 Write の RAID 1) に関してはバラツキが大きく、信頼性に欠ける結果です。
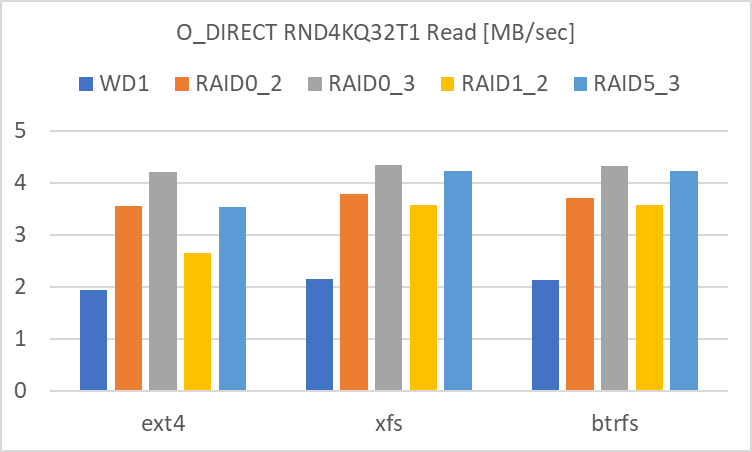
RND4KQ32T1
RND4KQ32T1 については、SEQ1M と傾向が異なります。
Read に関しては、
- RAID 0 (3基)
- RAID 5 (3基)
- RAID 0 (2基)
- RAID 1 (2基)
- 単体
の順でした。RAID 0 の HDD の数の増加でアクセス速度は向上しますが、SEQ1M の時とは異なり、2基と3基の差が縮まっています。
また、RAID 5 と RAID 1 のアクセス速度の向上が目立ちます。RND4KQ32T1 Read だけを考えれば、RAID 5 又は RAID 1 を選択して、冗長性に加えてアクセス速度の向上が期待できます。
Write に関しては、
- RAID 0 (3基)
- RAID 0 (2基)
- 単体、RAID 1 (2基)
- RAID 5 (3基)
の順でした。Read と同様に RAID 0 の HDD の数の増加によるアクセス速度の向上は頭打ちになっているようです。
RAID 1 は、Read は並列化の影響を受けて良化していますが、Write は単体と変わらない結果でした。
RAID 5 は、Write は極端にアクセス速度が低下しました。Read が良かっただけに、パリティの計算と書き込みに時間を要しているのでしょう。
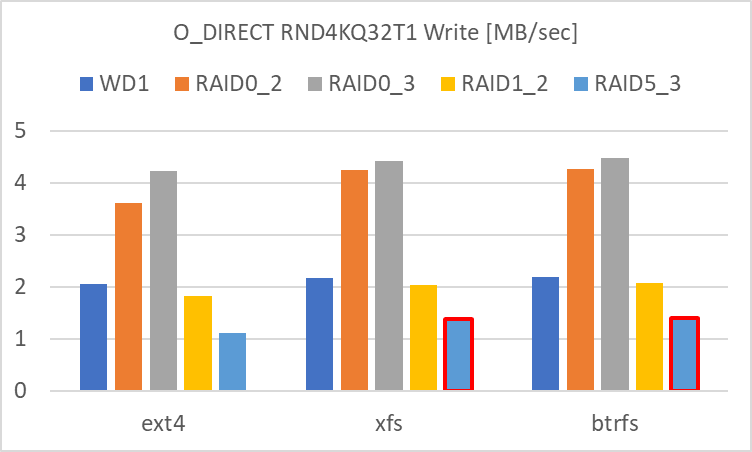
赤枠で囲った部分 (XFS / Btrfs Write の RAID 5) に関してはバラツキが大きく、信頼性に欠ける結果です。
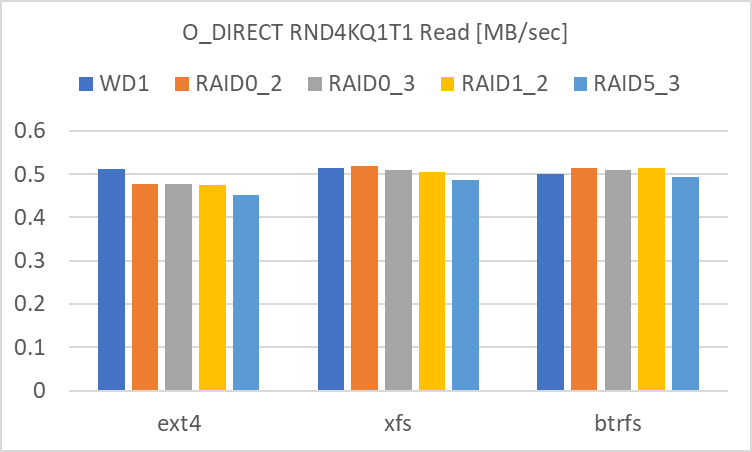
RND4KQ1T1
RND4KQ1T1 の Read では、どの RAID level でも単体とほぼ変わらない結果でした。iodepth=32 の場合は差が生じていましたが、iodepth=1 では変わらない結果でした。
Write に関しては、
- RAID 0 (3基)
- RAID 0 (2基)
- 単体
- RAID 1 (2基)
- RAID 5 (3基)
という結果でした。RAID 0 の HDD 数の増加によりリニアにアクセス速度が向上しています。
RAID 1 は単体よりも劣る結果でした。これまでは単体と同等~良化の傾向でしたが、RND4KQ1T1 ではアクセス速度が下がりました。
RAID 5 は RND4KQ32T1 と同様にアクセス速度は最も低い結果でした。小さいサイズの Write は、RAID 5 は苦手にしているのでしょう。
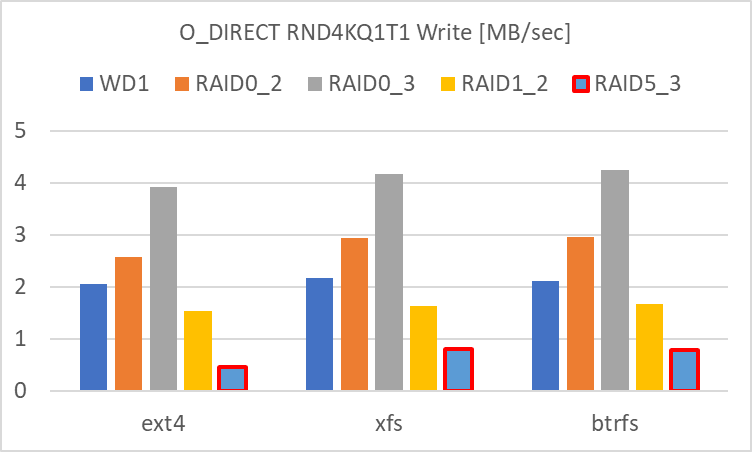
赤枠で囲った部分 (Ext4 / XFS / Btrfs Write の RAID 5) に関してはバラツキが大きく、信頼性に欠ける結果です。
Cache を使用しない場合の結果のまとめ
結果を一覧表にしました。
| RAID level | 単体 (WD1) | RAID0 (3基) | RAID0 (2基) | RAID 1 (2基) | RAID 5 (3基) |
| SEQ1MQ8T1 Read | 4 | 1 | 2 | 4 | 3 |
| SEQ1MQ8T1 Write | 4 | 1 | 2 | 4 | 3 |
| SEQ1MQ1T1 Read | 4 | 1 | 2 | 4 | 3 |
| SEQ1MQ1T1 Write | 4 | 1 | 2 | 4 | 3 |
| RND4KQ32T1 Read | 5 | 1 | 3 | 4 | 2 |
| RND4KQ32T1 Write | 3 | 1 | 2 | 4 | 5 |
| RND4KQ1T1 Read | 1 | 1 | 1 | 1 | 1 |
| RND4KQ1T1 Write | 3 | 1 | 2 | 4 | 5 |
- RAID 0 (3基, 2基) は冗長性を持たせない代わりに、特に Sequential access については SATA SSD 並みのアクセス速度を得る事が出来ます。動画や画像等の大容量のデータの仮置き場として、バックアップを前提として使用するのが良いかと思います。
- RAID 5 は冗長性とアクセス速度の向上をバランス良く有する RAID array です。ただし、RND4K Write が遅いので、メモリや SSD の Cache を併用すれば、最も使いやすい RAID array でしょう。
- RAID 1 は冗長性に特化しており、単体のアクセス速度とほぼ同等~若干劣る結果でした。RND4KQ32T1 Read のみ、単体よりもアクセス速度は速くなりました。
HDD の台数を確保できる前提で、RAID 5 (今回は台数不足で確認できませんでしたが RAID 6も) がバランスの良い RAID array だと私は考えます。
ちなみに、Windows11 には Software RAID に相当する記憶域という機能があります。記憶域については、私のはてなブログの日記で同じ HDD を使用して検証しましたので、興味のある方はご覧ください。
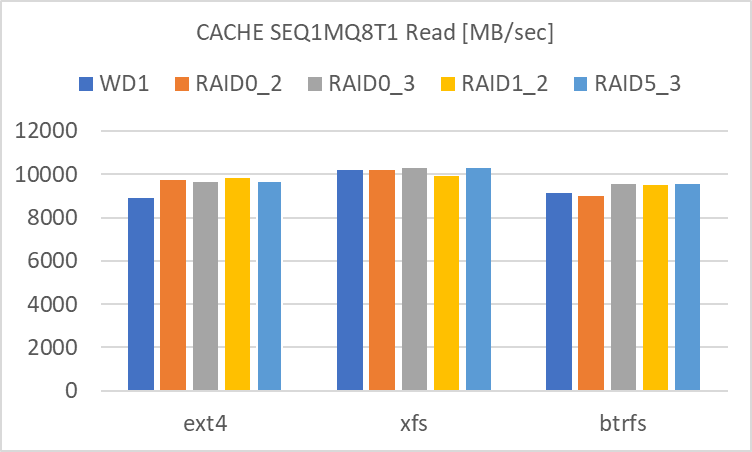
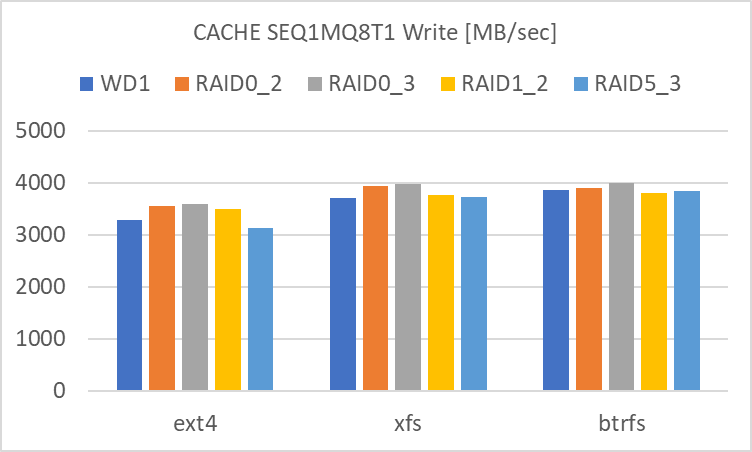
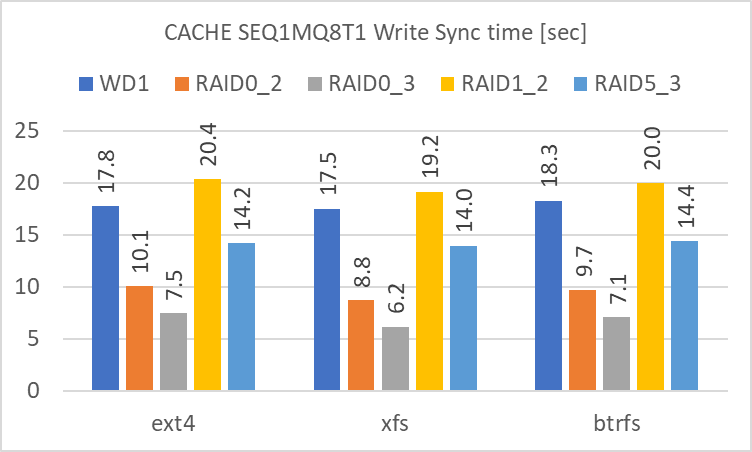
Cache を使用した場合の結果
次に、メインメモリによる Cache を使用した場合の結果です。こちらは最後にまとめてコメントしますので、グラフのみを列記します。
Read / Write / Write 後に Sync に要した時間の順です。
SEQ1MQ8T1
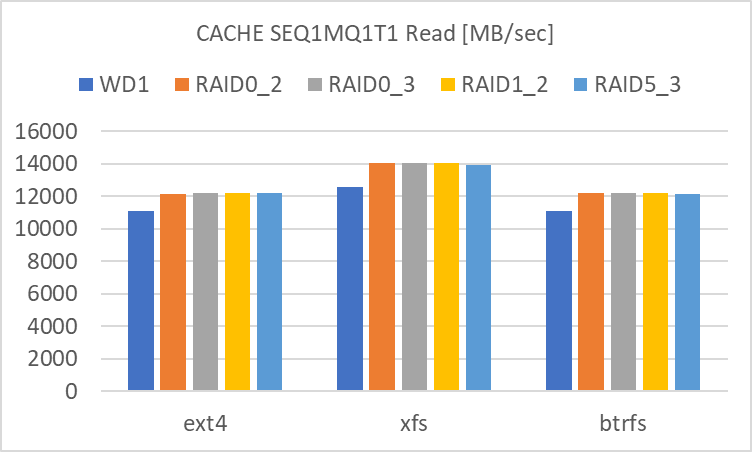
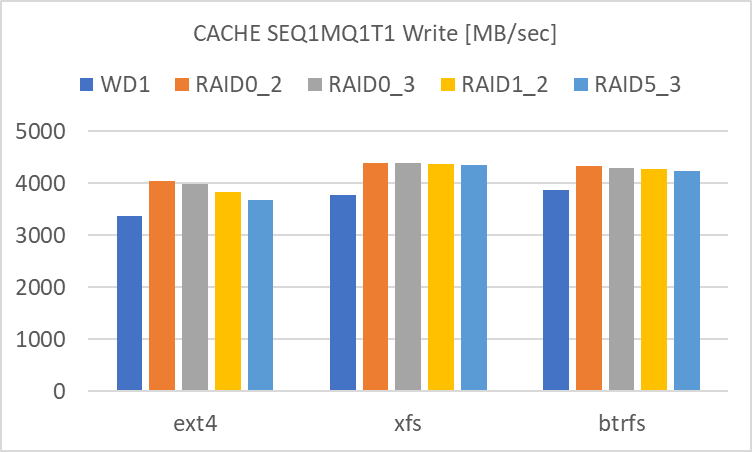
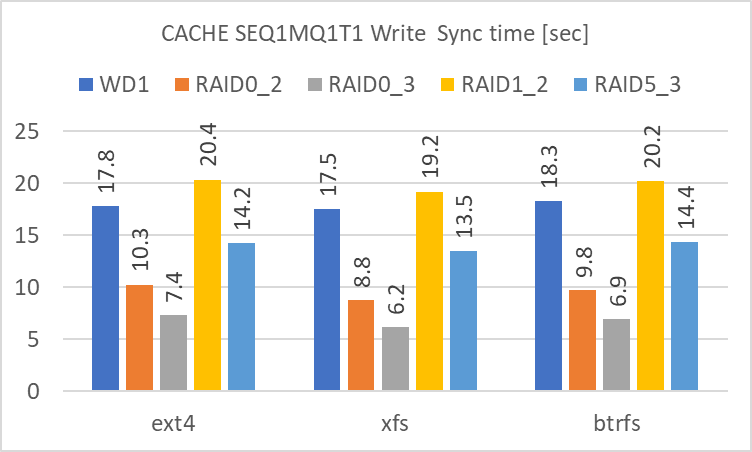
SEQ1MQ1T1
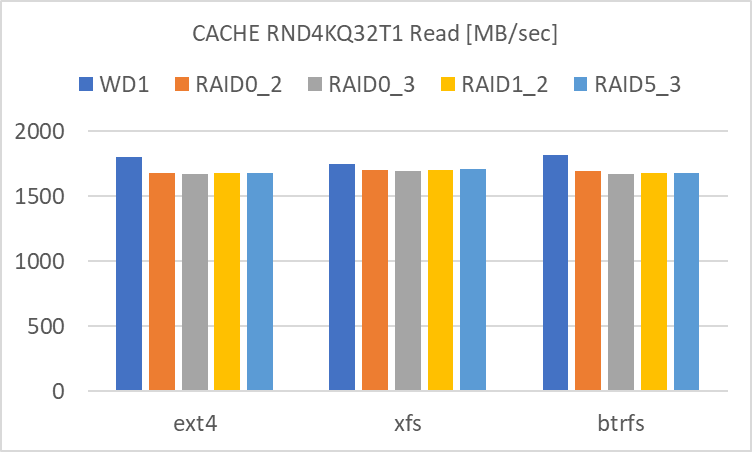
RND4KQ32T1
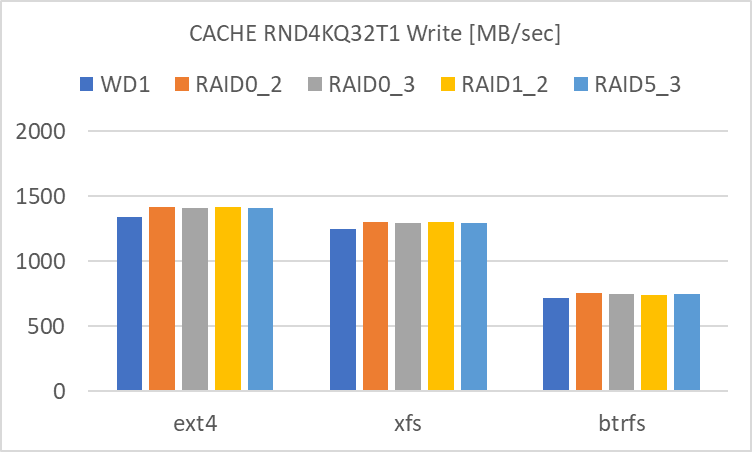
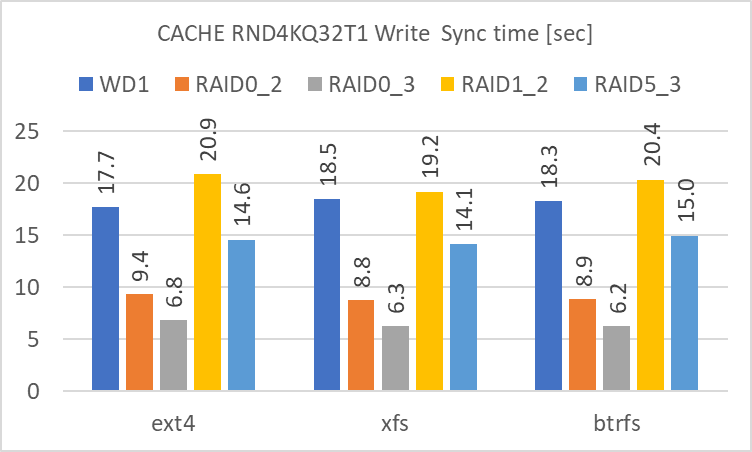
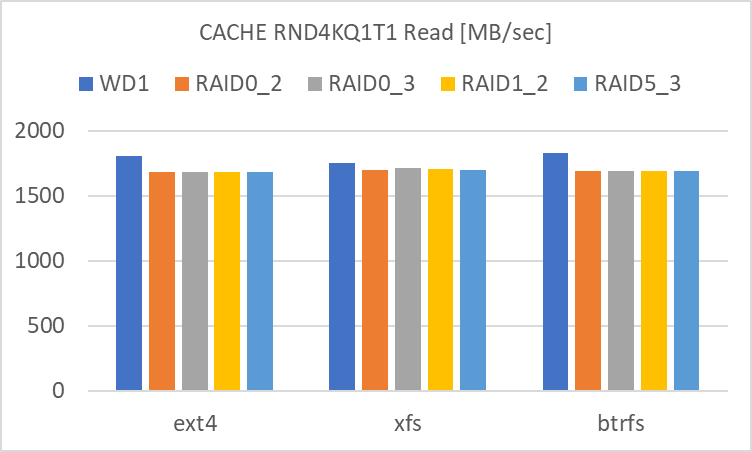
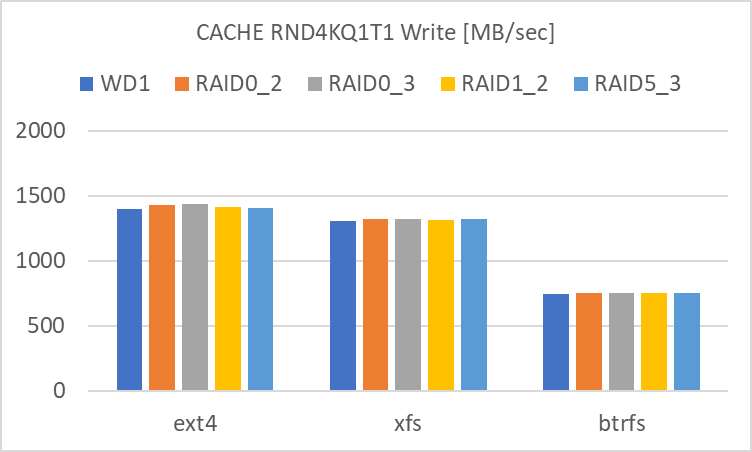
RND4KQ1T1
Cache による効果
Cache を使用しない場合には、RAID level によるディスクのアクセス速度に違いが生じていました。このアクセス速度は、長期間連続で Read / Write が発生した場合の下限の速度に相当します。
それに対して、メインメモリを Cache として使用した場合には、Cache に入っているデータの Read / Cache へのデータの Write を処理する速度に相当します。メインメモリとのデータのやり取りがメインとなり、ディスクへは遅延書込みされます。
その結果、
- RAID level による違いが殆ど見られません。単体でも RAID 0 でも、どちらも殆どアクセス速度は大差ありません。
- filesystem による違いは見られます。
- XFS は SEQ1M のアクセス速度が高めです。
- Btrfs は RND4K Write のアクセス速度が低めです。
という風に、Cache を使用しない時と比べて差が出にくい、極端に言えば RAID によるアクセス速度の向上効果が見えにくい状態です。
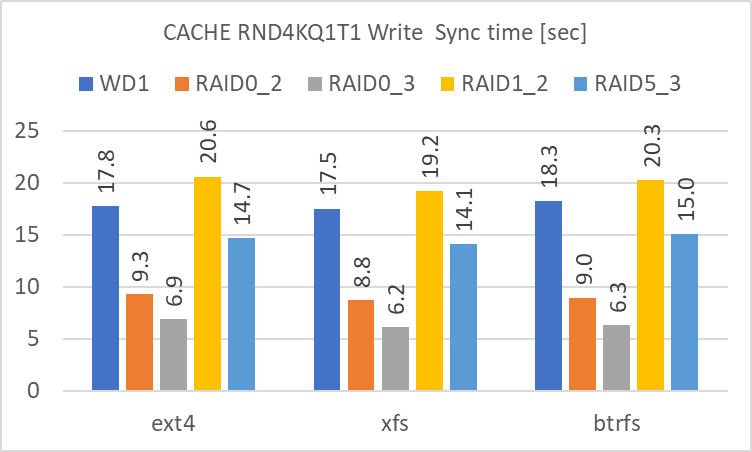
違いが明確に見られるのは、Write の後に sync を実行して実際にディスクに書き込む時間です。3GiB の sync に要する時間は、短い順に、
- RAID 0 (3基)
- RAID 0 (2基)
- RAID 5 (3基)
- 単体
- RAID 1 (2基)
となります。Cache を使用しない場合の Write のアクセス速度に準じますが、これが短いほど、急な電源断によるデータ喪失の可能性が低くなります。冗長性のある RAID level の中では RAID 5 が最も短時間で sync が終了していました。(現実的には SSD Cache を間に挟む等の対処が必要だと思いますが)
まとめ
mdadm を使用した Software RAID array を構築し、ディスクのアクセス速度を測定しました。
- 各 RAID level の特徴をまとめました。
- mdadm で RAID array を構築・確認・削除する方法をまとめました。
- RAID 0 (3基)、RAID 0 (2基)、RAID 1 (2基)、RAID 5 (3基) の RAID array のアクセス速度を測定しました。
- Cache を使用しない場合、Cache を使用した場合でそれぞれ測定し、単体のアクセス速度と比較しました。
結果をまとめると以下のようになります。
- 冗長性を考慮しない場合には、アクセス速度は RAID 0 (3基) が最も早く、Sequential access であれば SATA SSD 並みの速度で大容量のデバイスとして使用できます。ただし RAID 0 は 1基でも故障すると RAID array 全体のデータを失いますのでバックアップは必須です。
- 冗長性とアクセス速度向上のバランスの取れた RAID 5 が、HDD の台数を確保でき、RND4K の Write の速度が低い事を許容できるのであれば、最も使いやすいと思います。
- Cache を使用した場合のアクセス速度は、メインメモリの Cache の影響が大きく、RAID level による差が見られませんでした。ただし、Cache を sync する時間には差が生じています。冗長性を考慮すれば RAID 5 が短時間で sync が終了しているので、急な電源断等に対し安全だと思います。
今回のアイキャッチ画像
白猫を SDXL で生成しました。これまで三毛猫や黒猫が多かったので白猫を生成してみましたが、ちょっと厳しい表情でした。
今回使用している HDD は、
- WesternDigital Red WD40EFRX-RT2 (WD40EFRX-68N32N0) ... 2018年10月に購入
- Seagate IronWolf ST4000VN008 (ST4000VN008-2DR1) ... 2018年11月に購入
です。何方も5年以上 (NASで3年、PCで2年以上) 使用していますが、当たりだったのかトラブルなしで現役です。(2010年10月に購入した PC に入っていた HGST の 1TB HDD も現役です…14年目)






























どちらも CMR 方式の HDD です。SMR は未だ経験なし。大丈夫とは思いますが…


コメント