
WordPress のアイキャッチ画像を Stable Diffusion で作りたい
はてなブログの「hiro の長い冒険日記」の頃からの課題ですが、WordPress で日記を書くようになっても毎回悩むのがアイキャッチ画像です。無料の画像を使用するとしても、なかなかイメージに合うものが見つからず、といっても自分の手持ちの写真で風景を撮ったものは多くありません(9割仕事、1割家族)。画像のサイズも 1200 x 630 が最適らしいのですが、トリミングをするのもひと手間を要して、更に悩ましい状態でした。
昨年2022年8月に公開されて大きな話題となった画像生成 AI の Stable Diffusion について、興味はありましたが中々環境構築するまでに至りませんでした。機械学習目当てで購入した nVidia RTX3060 12GB も活用できておらず、なんとかしたいという気持ちが強くなってきました。
そこで、アイキャッチ画像の課題を解消する事と nVidia RTX3060 12GB を活用する事の二つを目的として、画像生成 AI の Stable Diffusion の環境を WSL2 Ubuntu 22.04 LTS に作ってみる事にしました。
20230822 追記 :
最新の Stable Diffusion WebUI をゼロからインストールし、Stable Diffusion XL 1.0 のモデルを使用する方法についてまとめました。PyTorch-2.0.1 & CUDA 11.8 です。

最初に試した Stable Diffusion の環境
「画像を生成するだけのシンプルな構成」という謳い文句に惹かれて、最初に下記のページの方法を試しました。

手順通りに進めるだけで、WSL2 Ubuntu 22.04 LTS で 256 x 256 ピクセルの画像を1枚ずつ作成するシンプルな環境を作る事が出来ました。
PPA (Personal Package Archive) を使う事なく、WSL2 Ubuntu 22.04 LTS の標準の apt line、pip だけで構成されています。環境構築を通して、Python の仮想環境 (venv) やパッケージ管理 (pip) の使い方、Stable Diffusion に必要なパッケージ、学習済みモデル、AI による画像の作成方法等について学びました。
とはいえ、不満もありました。
- 1枚ずつ作成するので試行錯誤しにくい。直ぐに確認出来ないのでやり直しが多い。
- 256 x 256 ピクセルで生成されるので、アイキャッチ画像(1200 x 630ピクセル) にするには横に引き伸ばす必要がある
- 引き延ばした影響もあり、少しぼやけた画像に見える
この環境を使用して何枚かの画像を生成し、PowerToys の Image Resizer で 1200 x 630 に伸張して、アイキャッチ画像に使用しました。
環境構築の始めの一歩としては、勉強になる事の多い経験でした。
本家 Stable Diffusion の環境構築 ~失敗~
ちゃんとした Stable Diffusion の環境を作ってみたいと考えて、ググってみましたが、先程のページに書かれている「結局なにが必要なのか分かりにくい、ごちゃごちゃと必要のないものもたくさんインストール」の言葉通り、手順通り実行しても真面に動作しませんでした。
そのような中でも手順がシンプルな物を試してみました。
%22%20transform%3D%22translate(.5%20.5)%22%20fill-opacity%3D%22.5%22%3E%3Cellipse%20fill%3D%22%2300408b%22%20rx%3D%221%22%20ry%3D%221%22%20transform%3D%22rotate(90.4%2032.4%2038.2)%20scale(10.76701%20158.99999)%22%2F%3E%3Cellipse%20fill%3D%22%23fffaef%22%20rx%3D%221%22%20ry%3D%221%22%20transform%3D%22rotate(-179.4%2037.9%2025.6)%20scale(76.24792%2022.87228)%22%2F%3E%3Cpath%20fill%3D%22%23095e98%22%20d%3D%22M144%200h16v24h-16z%22%2F%3E%3Cellipse%20fill%3D%22%23cfc7bf%22%20cx%3D%2274%22%20cy%3D%2289%22%20rx%3D%2261%22%20ry%3D%2226%22%2F%3E%3C%2Fg%3E%3C%2Fsvg%3E)

上記のページは手順がシンプルでしたので、WSL2 の Ubuntu 22.04 LTS、Ubuntu 20.04 LTS で試してみましたが撃沈。環境が作られたように見えても、動作させると進まなかったり、エラーが発生したり、と画像を作成する所までたどり着けませんでした。(私の選んだ環境が良くなかったのだと思います)
Stable Diffusion 2 と 2.1 の学習済みモデルの入手方法が分かったのが収穫でした。最近はユーザー登録不要なんですね。
Stable Diffusion WebUI の環境構築 ~成功~
その後もググっては試す、の繰り返しでしたが、docker で構築済みの環境を使おうかと考え始めました。
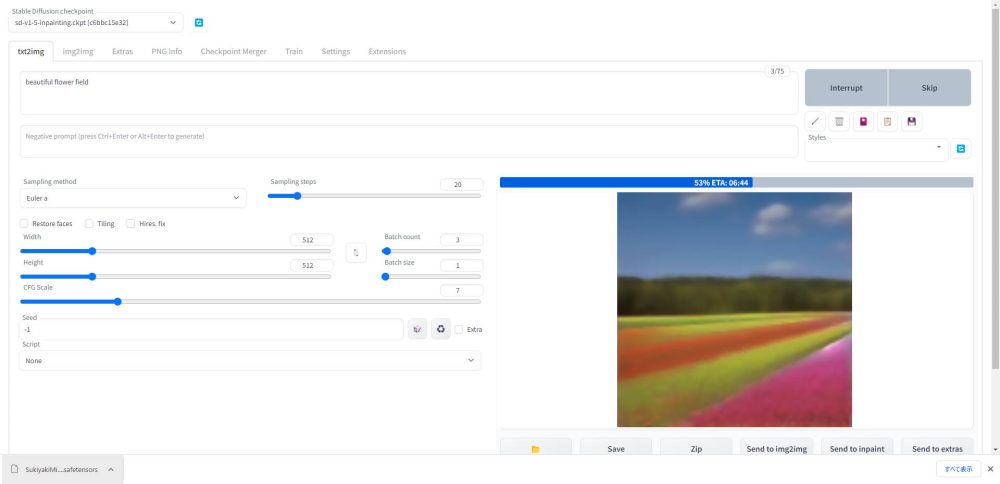

ここで初心に戻って、Stable Diffusion WebUI の公開元のインストール方法を調べてみました(結果的には、これを先に見るべきでした)。公開元の手順でインストールした所、スムーズに環境を構築する事が出来ました。
WSL2 Ubuntu 22.04 LTS に Stable Diffusion WebUI の環境を構築する

ここからが本題です。
Windows11 WSL2 Ubuntu 22.04 LTS に Stable Diffusion WebUI の環境を構築する手順について説明します。前提となる環境は以下の通りです。
$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 22.04.1 LTS
Release: 22.04
Codename: jammy
$ python3 -V
Python 3.10.6
$ dpkg -l | grep -i 'nvidia-cuda-toolkit ' | tr -s ' ' ' '
ii nvidia-cuda-toolkit 11.5.1-1ubuntu1 amd64 NVIDIA CUDA development toolkit
$ nvidia-smi
Wed Feb 15 23:02:17 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.89.02 Driver Version: 528.49 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
...snip...Windows11 の nVidia RTX3060 用のドライバは最新にしています。nvidia-smi コマンドは Ubuntu 側ではなく Windows11 側でビデオカードのドライバから用意されます。
nvidia-cuda-toolkit は nVIDIA のサイトからダウンロードする 11.6 で紹介している記事が多いですが、Ubuntu 22.04 の apt にある 11.5 でも Stable Diffusion WebUI は動作します。
Windows11 に WSL2 Ubuntu 22.04 LTS をインストール
こちらは事例がたくさんありますので省略します。Microsoft Store でも wsl --install でもどちらでも構いません
WSL2 Ubuntu 22.04 LTS を最新の環境にアップデート
こちらも事例がたくさんあります。以下のコマンドを実行すればOKです。
$ sudo apt update
$ sudo apt -y upgrade必要なパッケージを事前準備
事前に必要なパッケージは、WebUI のページに書かれています。
# Debian-based:
sudo apt install wget git python3 python3-venvこれに加えて nvidia-cuda-toolkit パッケージをインストールしておく必要があります。
sudo apt install nvidia-cuda-toolkit前述の通り、バージョンは 1.15 ですが動作しますので問題ありません。
Stable Diffusion WebUI のインストール
Stable Diffusion WebUI のインストール方法は三種類あります。
- webui.sh のみダウンロードして実行 (Automatic Installation on Linux)
- github から clone (preferred way: using git)
- zip ファイル落として展開 (alternative way)
おすすめは2番目の方法です。以下、2番目の方法でのインストール方法について記載します。
git clone でインストール
git clone
ユーザーの home ディレクトリで git clone コマンドを実行します。
$ cd
$ git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitすると、~/stable-diffusion-webui 以下に WebUI がクローンされます。
webui_user.sh の編集
xformers を有効にするために、webui_user.sh 内の COMMANDLINE_ARGS の先頭の # を消して有効にして、xformers のオプションを入力します。
export COMMANDLINE_ARGS="--xformers"こうする事で xformers が pip でインストールされます(xformers をコンパイルする必要はありません)。nVidia RTX3060 12GB の場合は大丈夫でしたが、メモリ不足等を生じる場合には、こちらにオプションを追記します。
学習済みモデルのダウンロード
~/stable-diffusion-webui/models/Stable-diffusion のディレクトリで、以下のコマンドで学習済みモデルをダウンロードします。最初はどれか一つがあれば良いかと思います。それぞれ5GB以上ありますので、ダウンロードにはそれなりに時間を要します。
Ver.2.1 : v2-1_768-ema-pruned
$ wget https://huggingface.co/stabilityai/stable-diffusion-2-1/resolve/main/v2-1_768-ema-pruned.safetensorsVer.2.1 : v2-1_512-ema-pruned
$ wget https://huggingface.co/stabilityai/stable-diffusion-2-1-base/resolve/main/v2-1_512-ema-pruned.safetensorsVer.2.0 : 768-v-ema
$ wget https://huggingface.co/stabilityai/stable-diffusion-2/resolve/main/768-v-ema.safetensorsckpt ではなく safetensors なのは以下の理由です。

webui.sh の実行 (インストール)
~/stable-diffusion-webui 以下で webui.sh を実行すれば、必要なパッケージのインストールが始まります。
$ ./webui.sh
...snip...
Running on local URL: http://127.0.0.1:7860
初回のみインストールに時間を要しますが、2回目以降は直ぐに起動します。
ブラウザで接続
'a photo of an astronaut riding a horse on mars' です。
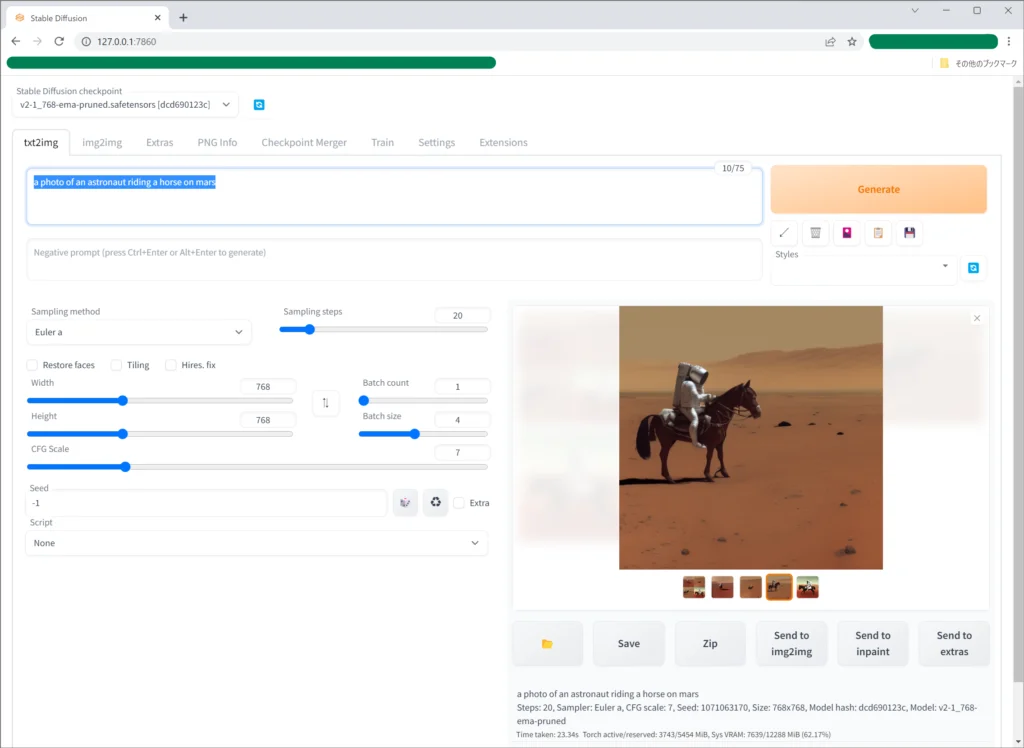
nVidia RTX3060 12GB で 4枚生成して20秒位です。Width と Height を指定すれば、1200 x 630 ピクセルの画像も作成できます。
webui.sh について
webui.sh が便利に出来ています。
- github からの pull
- python venv による仮想環境の構築
- パッケージのインストール (pip) インストール済みならスキップ
- 学習済みモデルの確認 インストールされていなければ一旦停止して催促
- 全てインストール済みなら Web サーバとして起動
という形で、必要なパッケージをインストール & 確認して、必要なら再インストールしてくれます。
まとめ
Windows11 の WSL2 Ubuntu 22.04 LTS に Stable Diffusion WebUI の環境を構築しました。
まだ使い始めで、呪文の作り方や他の機能を少しずつ試している所です。当初想定していたよりも画像の生成は速いと感じました。768 x 768 ピクセルなら 4枚で20秒、1200 x 630 ピクセルなら4枚で30秒程です。
これでちゃんと画像の生成は出来ていますが、もし間違い等ありましたらコメント欄から教えて頂けると幸いです。
今日のアイキャッチ画像
Stable Diffusion WebUI で 'a photo of an astronaut riding a horse on mars' で 1200 x 630 ピクセルで作成した画像です。この先も呪文を勉強します。


コメント