
はじめに
私は Stable Diffusion WebUI を使用して SDXL 1.0 で画像を生成し、この日記のアイキャッチ画像を生成しています。画像生成 AI を使いたいが為に、ビデオカードは nVidia RTX3060 12GB を購入しました。VRAM の容量が多めで安価なもの、という基準で選択しました。


画像生成以外の AI としては、最近は大規模言語モデル (Large Language Models, LLM) を使用したテキスト生成 AI の進歩が急激に進んでいます。最も有名なのは OpenAI の ChatGPT で、私も無料版の ChatGPT-3.5 を試用iしています。日記の記事に直接は使用していませんが、初期のアイデアを形にする段階で利用したり、プログラム例を問い合わせたりという用途に使用しています。
とはいえ、画像生成 AI と同様に自宅の PC でテキスト生成 AI を使ってみたいと常々考えていました。特に日本語に特化したテキスト AI を使用できれば、更に用途が広がるのではないかと感じていました。
試しに、2023年11月に公開された CyberAgent 社の日本語 LLM である Calm2-7B (CyberAgentLM2 - 7B) を Text generation web UI で試した所、制限はあるものの比較的容易に環境を構築する事が出来ました。
今回の記事では、テキスト生成 AI の Web UI である Text generation web UI で日本語 LLM の Calm2-7B を使用する方法について説明します。
Calm2-7B (CyberAgentLM2-7B) について
Calm2-7B (CyberAgentLM2-7B) は、2023年11月2日に CyberAgent社が公開した、独自開発の日本語 LLM です。

プレスリリースに書かれている特徴は以下の通りです。
- 2023年5月に公開された CyberAgentLM の Version 2
- 70億パラメータ・32,000トークン対応 (日本語の文章として約50,000文字を一度に処理可能)
- ベースモデルの Calm2-7B とチャット形式でチューニングした Calm2-7B-Chat の2種類
- 商用利用可能な Apache License 2.0 で提供
Apache License 2.0 というのが嬉しい所です。
Text generation web UI について
テキスト生成 AI 版の Stable Diffusion WebUI を目指して開発されている、LLM 用の Web UI です。

LLM をダウンロード・選択・切り替える事ができ、テキスト生成も Web のユーザーインターフェースで実行する事が出来ます。
インストール方法
Text generation web UI を使用する環境
Windows での環境構築例が多いですが、個人的な好みから WSL2 に Text generation web UI の環境を作成します。Stable Diffusion WebUI & SDXL 1.0 用に準備した環境を利用します。
WSL2 Ubuntu 23.04 & Python 3.11.4 & CUDA-11.8 を使用します。
$ cat /etc/os-release
PRETTY_NAME="Ubuntu 23.04"
NAME="Ubuntu"
VERSION_ID="23.04"
VERSION="23.04 (Lunar Lobster)"
VERSION_CODENAME=lunar
ID=ubuntu
ID_LIKE=debian
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
UBUNTU_CODENAME=lunar
LOGO=ubuntu-logo
$ python3 -V
Python 3.11.4
$ /usr/local/cuda-11.8/bin/nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Sep_21_10:33:58_PDT_2022
Cuda compilation tools, release 11.8, V11.8.89
Build cuda_11.8.r11.8/compiler.31833905_0WSL2 以外にも、Ubuntu 等の Linux でも同様に環境構築できると思います。CUDA は今回は Ver. 11.8 を使用しましたが、Ver.12.1 にも対応しているようです。
Text generation web UI のインストール
Text generation web UI の github のインストール手順を見ると、各環境用の install script が準備されており、実行するだけで環境構築が出来るようです。しかし、install scirpt の中をみると、Python の環境構築に conda (Anaconda) を使用しています。
普段は pip を使用して conda は使用しておらず、pip と conda は「混ぜるな危険」と言われています。Stable Diffusion WebUI が pip を使用している事もあり、Text generation web UI も pip で環境を構築する事にしました。以下のページを参考にしました。

Windows へインストールした例ですが、少し修正すれば WSL2 Ubuntu にも適用できます。
git clone
Text generation web UI の github から clone します (install script は使用しません)。
$ git clone https://github.com/oobabooga/text-generation-webui
Cloning into 'text-generation-webui'...
remote: Enumerating objects: 13855, done.
remote: Counting objects: 100% (296/296), done.
remote: Compressing objects: 100% (177/177), done.
remote: Total 13855 (delta 172), reused 213 (delta 119), pack-reused 13559
Receiving objects: 100% (13855/13855), 24.28 MiB | 23.14 MiB/s, done.
Resolving deltas: 100% (9494/9494), done.text-generation-webui ディレクトリが作成され、必要なファイルが clone されます。
Python 仮想環境の作成
venv で Python の仮想環境を作成します。venv が入っていない場合には、予めインストールしておきます。Stable Diffusion を使用していれば既にインストール済みです。
$ sudo apt install python3-venv環境構築に失敗した場合も venv 以下を削除するだけですので、他の Python 環境に影響を与えずに作業できるので安心です。
$ cd text-generation-webui/
$ python3 -m venv venv
$ source ./venv/bin/activate
(venv) $これ以降の作業は Python venv 仮想環境の中で実行します。
PyTorch のインストール
PyTorch のサイトで、条件を指定してインストールするコマンドを取得します。

- PyTorch Stable (2.1.0)
- Linux
- Pip
- Python
- CUDA 11.8

を選択して、下部に表示されるコマンドを実行します。
(venv) $ pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118CUDA と仮想環境の Python のバージョンに合わせた torch と torchvision、torchaudio がインストールされます。
他の Python パッケージのインストール
github から clone した requirements.txt は CUDA 12.1 & 12.2 用なので、CUDA 11.8 用に修正します。sed で +cu121 と +cu122 を +cu118 に書き換えます。
作成した requirements_cu118.txtを使って、残りのパッケージをインストールします。
(venv) $ cat requirements.txt | sed 's/+cu12[12]/+cu118/g' > requirements_cu118.txt
(venv) $ pip3 install -r requirements_cu118.txt+cu122 (CUDA 12.2) 向けのパッケージが残っているとモデルの読み込みに失敗します。+cu121 と +cu122 の両方を +cu118 に書き換える必要があります。
Text generation web UI の起動
各種パッケージのインストールが終わりましたので、Text generation web UI を起動します。
(venv) $ python3 server.py
2023-11-08 21:08:37 INFO:Loading the extension "gallery"...
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
Stable Diffusion WebUI と同様に、localhost の Port 7860 をウェブブラウザで読み込むと、Text generation web UI が表示されます。(クリックすると拡大します)

この画面が表示できれば、Text generation web UI のインストールは正常に行えています。
Calm2-7B のダウンロード
Text generation web UI をインストールしただけでは、LLM はダウンロードされていません。Model タブの右側の部分で LLM をダウンロードします。
CyberAgent 社の日本語 LLM は Hugging Face に置かれています。ユーザー登録は必要なく、誰でもダウンロードできます。

この中で、CyberAgentLM の Version 2 は次の二つです。
- cyberagent/calm2-7b
- cyberagent/calm2-7b-chat
このどちらか (あるいは両方) を Text generation web UI からダウンロードします。
Download model or LoLA の下の入力欄に、Hugging Face のモデル名を入力して「Download」を押します。

成功すると、この箇所の下に「Done!」のメッセージが表示されます。Text generation web UI を起動した WSL2 Ubuntu のコンソールには、ダウンロードの進捗が表示されます。合計で約14 GB のファイルが models ディレクトリ以下にダウンロードされます。
Downloading the model to models/cyberagent_calm2-7b
100%|██████████████████████████████████████████████████████████████████████████████████| 1.93k /1.93k 30.9MiB/s
100%|██████████████████████████████████████████████████████████████████████████████████| 664 /664 9.31MiB/s
100%|██████████████████████████████████████████████████████████████████████████████████| 132 /132 2.10MiB/s
100%|██████████████████████████████████████████████████████████████████████████████████| 23.9k /23.9k 76.8MiB/s100%|██████████████████████████████████████████████████████████████████████████████████| 585 /585 6.67MiB/s100%|██████████████████████████████████████████████████████████████████████████████████| 674 /674 10.2MiB/s
100%|██████████████████████████████████████████████████████████████████████████████████| 3.27M /3.27M 3.72MiB/s100%|██████████████████████████████████████████████████████████████████████████████████| 4.04G /4.04G 48.0MiB/s
100%|██████████████████████████████████████████████████████████████████████████████████| 9.98G /9.98G 68.0MiB/s
100%|██████████████████████████████████████████████████████████████████████████████████▉| 9.97G /9.98G 102MiB/sCalm2-7B の読み込み
Calm2-7B のダウンロードが済んだら、モデルを読み込みます。Model タブの左側の上部、Model の下のセレクトボックスから LLM 名を選択します。表示されない場合には再読み込みのマークを押し、一度 None を選択してから LLM 名を選択します。
二つの項目 (load-in-8bit, use_fast) のチェックを入れてから「Load」を押して LLM を読み込みます。

nVidia RTX3060 12GB で Calm2-7B を使用する為には、二つの項目のチェックを入れる必要があります。
- load-in-8bit
- use_fast
一つ目は VRAM の使用量を減らす為の設定です。Calm2-7B を使用する為には、通常は nVidia RTX4090 等の 24GB の VRAM を必要とします。load-in-8bit のチェックを入れる事で VRAM 12GB の nVidia RTX3060 でも Calm2-7B を使用する事が出来ます (ただしテキスト生成の精度は落ちると思います)。load-in-8bit のチェックを入れると、約80% (10GB) の VRAM を使用します。
二つ目は次のエラーの回避の為です。CyberAgentLM では必須のようです。
ValueError: Tokenizer class GPTNeoXTokenizer does not exist or is not currently imported.
Successfully loaded の文字が表示されればモデルの読み込みは成功です。モデルの読み込みには約30秒を要しました。

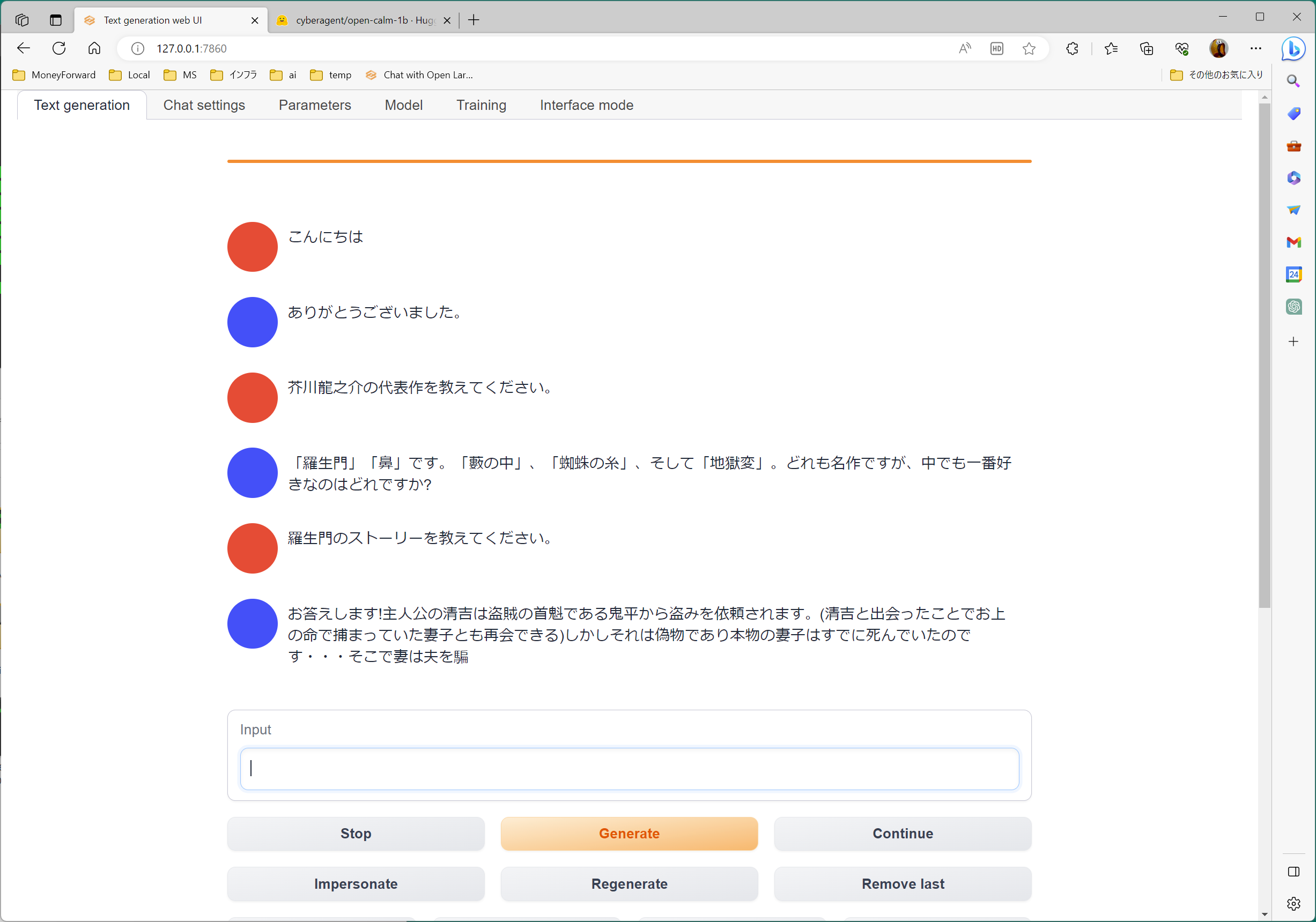
テキストを生成する
まだ使い始めたばかりで手探りの状態ですが、Calm2-7B を使用して Chat タブに「これから AI が活用される分野を三つ教えて」と聞いた場合の答えです。

nVidia RTX3060 12GB で全ての文章が表示されるまで1分程度です。ChatGPT 3.5 にはかないませんが、それなりの文章が生成されていると思います。
Calm2-7b-Chat を使用すると、短めのテキストが生成されるようです。
どちらの LLM についても、もう少し使い込んでみます。
回答が日本語にならない場合の対処法については、以下のページを参考にしました。
少し古い情報ですが、日本語で回答を受け取る方法については、現在の Text generation web UI でも参考になります。
まとめ
テキスト生成 AI 用の Web UI である Text generation web UI で、CyberAgent社の日本語 LLM の Calm2-7b、Calm2-7b-Chat を使ってみました。
- WSL2 Ubuntu 23.04 に環境を構築しました。
- Text generation web UI の install script は conda で環境構築するので使用せず、venv と pip を使用しました。
- nVidia RTX3060 12GB で Calm2-7b、Calm2-7b-Chat を使用する場合には、Text generation web UI の load-in-8bit と use_fast オプションを有効にする必要がありました。
- VRAM は約80%、10GB を使用し、それなりの速度でテキストを生成できました。
- 生成されるテキストの品質は、少し使用した感じでは ChatGPT 3.5 には敵わないと思いますが、それなりに意味のある文章を生成できているようでした。
nVidia RTX3060 12GB でもテキスト生成 AI が使用できるようになりました。生成されるテキストの品質は、この先も改良されて、より良くなっていく事が期待できます。この先も新しい技術が公開された時に早めのタイミングで試用してみたいと考えています。
色々試す中で、やはりビデオカードの能力 & VRAM の影響は大きいと感じています。本気でローカルのPC で AI に取り組むとしたら、RTX4090 辺りを用意しないと、世の中の最新の情報についていくのは厳しいです。
今回のアイキャッチ画像
雪の町を生成しました。北国では初雪が降り始めました。冬到来ですが、関東はこれから乾燥期に入ります。住んで10年を超えましたが、未だに冬の空気の乾燥には慣れません。


コメント